#Short Answer
Explains What Is a Transformer Model, including the core definition, how it works, practical examples, and limitations.
#Infobox
#Overview
The Transformer model represents a paradigm shift in machine learning, particularly in handling sequential data such as text, audio, and time-series. Unlike earlier architectures like Recurrent Neural Networks (RNNs) or Long Short-Term Memory (LSTM) networks, which process data sequentially, Transformers rely entirely on self-attention mechanisms to weigh the importance of different parts of the input data relative to each other. This allows them to capture long-range dependencies efficiently and process entire sequences in parallel, significantly improving training speed and scalability. Transformers have become the backbone of modern Natural Language Processing (NLP) systems, enabling breakthroughs in tasks such as:
- Machine translation (e.g., Google Translate)
- Text summarization
- Question answering (e.g., chatbots, search engines)
- Sentiment analysis
- Code generation (e.g., GitHub Copilot)
- Multimodal applications (e.g., image captioning, video analysis) Their versatility has led to the development of large language models (LLMs) like GPT-3, BERT, and PaLM, which demonstrate human-like text generation and comprehension capabilities.
#History / Background
#Predecessors and Motivations Before Transformers, sequence modeling relied heavily on RNNs and LSTMs, which process data sequentially and struggle with vanishing gradients and parallelization. These limitations made training large models computationally expensive and slow. Additionally, Convolutional Neural Networks (CNNs) were used for some sequence tasks but lacked the ability to model long-range dependencies effectively.
#The Birth of the Transformer The Transformer architecture was introduced in the landmark paper "Attention Is All You Need" by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin (Google Brain), published at NeurIPS 2017. The paper proposed replacing recurrent layers with self-attention, a mechanism that allows the model to dynamically focus on relevant parts of the input sequence. Key motivations behind the Transformer included:
- Parallelization: Enabling efficient training on GPUs/TPUs by processing entire sequences simultaneously.
- Long-range dependencies: Capturing relationships between distant words in a sentence without the bottlenecks of sequential processing.
- Scalability: Supporting larger models and datasets, which was infeasible with RNNs.
#Evolution and Impact The Transformer’s success led to rapid adoption and innovation:
- 2018: BERT (Bidirectional Encoder Representations from Transformers) introduced by Google, leveraging Transformers for bidirectional context understanding.
- 2019: GPT-2 (Generative Pre-trained Transformer 2) by OpenAI demonstrated large-scale text generation.
- 2020: T5 (Text-to-Text Transfer Transformer) unified NLP tasks under a single model.
- 2021–2023: GPT-3, PaLM, and LaMDA pushed the boundaries of generative AI, enabling human-like conversations and creative writing. Transformers also expanded beyond NLP into computer vision (e.g., Vision Transformer (ViT)), audio processing, and reinforcement learning, proving their adaptability.
#How It Works
#Core Components The Transformer architecture consists of two main parts:
- Encoder: Processes the input sequence and generates contextual representations.
- Decoder: Generates the output sequence step-by-step, using the encoder’s representations.
1. Self-Attention Mechanism At the heart of the Transformer is self-attention, which allows the model to relate different positions of a single sequence to compute a representation. For each word in a sentence, the model calculates:
- Query (Q): Represents the current word.
- Key (K): Represents other words in the sequence.
- Value (V): Represents the content associated with each word. The attention score between two words is computed as: \[ \textAttention(Q, K, V) = \textsoftmax\left(\fracQK^T\sqrtd_k\right)V \] where (d_k) is the dimension of the key vectors. This score determines how much focus to place on each word when processing the current word.
2. Multi-Head Attention Instead of a single attention mechanism, the Transformer uses multi-head attention, where multiple attention layers (heads) run in parallel. Each head learns different relationships between words, and their outputs are concatenated and linearly transformed. This allows the model to capture diverse patterns (e.g., syntactic, semantic, and positional relationships).
3. Positional Encoding Since Transformers lack inherent sequential processing, they use positional encodings to inject information about the order of words in the sequence. These are typically sinusoidal functions or learned embeddings added to the input embeddings.
4. Feed-Forward Networks Each layer in the encoder and decoder contains a feed-forward neural network (a simple fully connected network) that processes the attention outputs independently for each position.
5. Layer Normalization and Residual Connections
- Layer normalization stabilizes training by normalizing the activations.
- Residual connections (skip connections) help mitigate the vanishing gradient problem by allowing gradients to flow directly through the network.
6. Decoder Components The decoder includes:
- Masked self-attention: Prevents the decoder from attending to future tokens during training (to maintain autoregressive properties).
- Encoder-decoder attention: Allows the decoder to focus on relevant parts of the input sequence.
#Training Process
Transformers are typically trained using:
- Supervised learning: Fine-tuning on labeled datasets (e.g., for translation or classification).
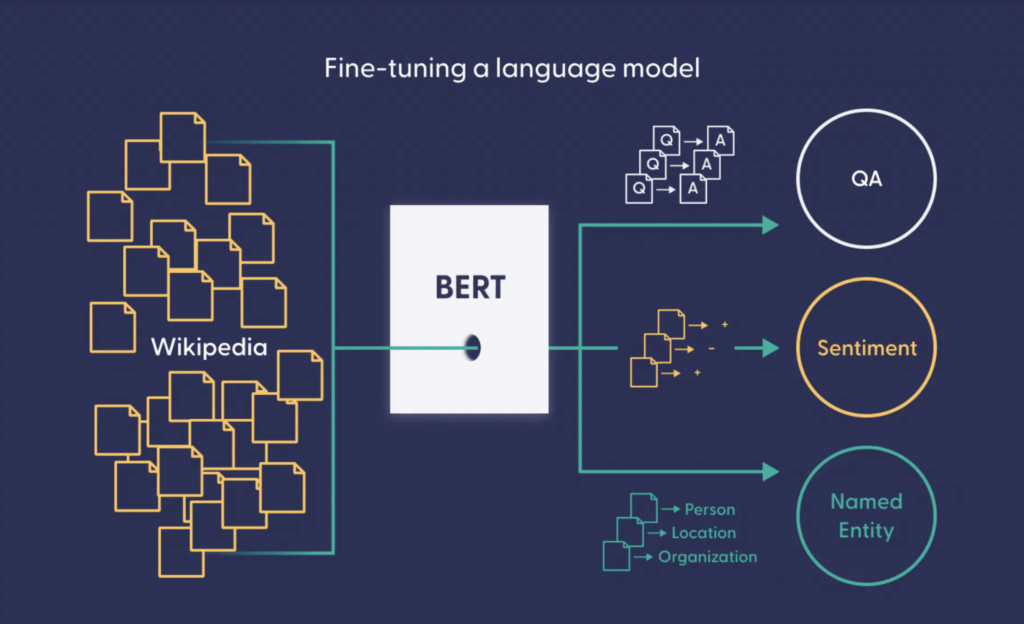
- Unsupervised pre-training: Training on large text corpora to learn general language representations (e.g., BERT’s masked language modeling).
- Reinforcement learning: For tasks like dialogue generation (e.g., RLHF in InstructGPT).
#Inference During inference, the decoder generates output tokens one by one, using the previously generated tokens as additional input (autoregressive generation).
#Important Facts
- Parallel Processing: Transformers process entire sequences simultaneously, unlike RNNs, which process data sequentially. This enables faster training on GPUs/TPUs.
- Scalability: Transformers can scale to billions of parameters (e.g., GPT-3 has 175 billion parameters), leading to emergent capabilities like few-shot learning.
- Attention as a Bottleneck: The self-attention mechanism has a quadratic complexity (O(n^2)) with respect to sequence length, limiting its use for very long sequences (e.g., >10,000 tokens).
- Positional Encoding Alternatives: Recent work explores rotary embeddings (e.g., in PaLM) and relative positional encodings to improve long-sequence modeling.
- Multimodal Transformers: Extensions like CLIP and DALL·E combine text and image data using Transformer-based architectures.
- Efficiency Improvements:
- Sparse Transformers: Reduce attention complexity by attending to a subset of positions (e.g., Longformer, BigBird).
- Linear Transformers: Approximate attention with linear complexity (e.g., Performer, Linformer).
- Hardware Optimization: Transformers are optimized for Tensor Processing Units (TPUs) and Graphics Processing Units (GPUs), with frameworks like TensorFlow and PyTorch providing efficient implementations.
#Timeline
- Foundational ideas
Core concepts and early methods shape What Is a Transformer Model?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does What Is a Transformer Model? cover?
Explains What Is a Transformer Model, including the core definition, how it works, practical examples, and limitations.
Why is What Is a Transformer Model? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Transformer, Model, AI before using the ideas in real projects.
#References
- What Is a Transformer Model? terminology and background research
- What Is a Transformer Model? use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Transformer case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.