
#Short Answer
Explains how to deploy an ai model, including the main process, tools, examples, risks, and practical implementation steps.
#Infobox
#Overview
Deploying an AI model refers to the systematic process of transitioning a trained machine learning model from a development environment into a live production system where it can deliver real-time or batch predictions. This process bridges the gap between model development and practical application, transforming theoretical algorithms into actionable tools that drive business decisions, automate workflows, and enhance user experiences. The deployment of AI models has become a cornerstone of modern digital transformation, enabling organizations across industries—such as healthcare, finance, retail, and manufacturing—to integrate intelligent decision-making into their core operations. As AI adoption accelerates, the ability to deploy models efficiently, reliably, and at scale has emerged as a critical competency for data science and engineering teams. Unlike traditional software development, AI model deployment introduces unique challenges such as managing model drift, ensuring low-latency inference, and maintaining data consistency across distributed environments. These complexities have led to the development of specialized deployment frameworks, DevOps practices for AI (often called MLOps), and robust monitoring systems to track model performance over time.
#History / Background
The concept of deploying AI models evolved alongside advancements in machine learning and cloud computing. In the early 2000s, AI models were largely confined to research labs and academic settings, with limited scalability due to hardware constraints and lack of standardized frameworks. The breakthrough came in the late 2000s and early 2010s with the rise of cloud platforms like Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure. These platforms provided scalable compute resources and storage, enabling organizations to train and serve larger models without investing in on-premise infrastructure. The introduction of open-source machine learning frameworks such as TensorFlow (2015) and PyTorch (2016) further democratized model development, allowing developers to build and iterate on models rapidly. Around the same time, containerization technologies like Docker (2013) and orchestration tools like Kubernetes (2014) began to gain traction, offering standardized ways to package and deploy applications—including AI models—across diverse environments. By the mid-2010s, the term MLOps emerged as a discipline combining machine learning, DevOps, and data engineering to streamline the deployment and management of AI models. This shift reflected a growing recognition that deploying AI was not a one-time event but an ongoing process requiring continuous monitoring, retraining, and versioning. The COVID-19 pandemic (2020–2022) accelerated AI adoption, particularly in healthcare, logistics, and customer service, pushing organizations to deploy models faster and more reliably. This period also saw the rise of edge AI, where models are deployed on local devices (e.g., smartphones, IoT sensors) to reduce latency and improve privacy. Today, AI model deployment is a mature field supported by a rich ecosystem of tools, platforms, and best practices, enabling organizations of all sizes to operationalize AI at scale.
#How It Works
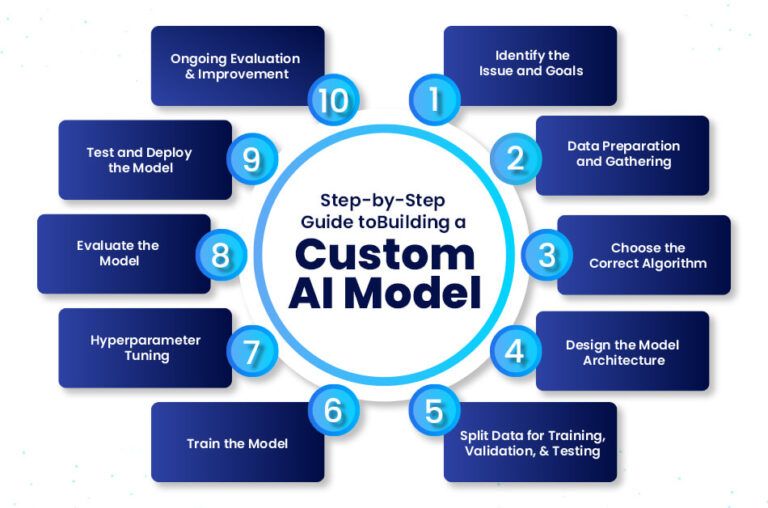
Deploying an AI model involves several interconnected stages, each designed to ensure the model operates efficiently, securely, and reliably in a production environment. Below is a step-by-step breakdown of the deployment process:
#
- Model Development and Training Before deployment, a machine learning model must be developed and trained using relevant datasets. This phase includes:
- Data Collection and Preprocessing: Gathering and cleaning data to remove noise, handle missing values, and normalize features.
- Feature Engineering: Creating meaningful input variables that improve model performance.
- Model Selection: Choosing an appropriate algorithm (e.g., neural networks, decision trees, support vector machines) based on the problem type (classification, regression, clustering).
- Training and Validation: Using training data to fit the model and validation data to tune hyperparameters and prevent overfitting.
- Evaluation: Assessing model performance using metrics such as accuracy, precision, recall, F1-score, or mean squared error. Once the model achieves satisfactory performance, it is saved in a format compatible with deployment tools (e.g., TensorFlow SavedModel, ONNX, Pickle).
#
- Model Optimization Optimizing the model for production involves reducing its size, improving inference speed, and minimizing resource usage without significantly degrading accuracy. Techniques include:
- Quantization: Reducing the precision of model weights (e.g., from 32-bit to 8-bit) to decrease memory usage and increase inference speed.
- Pruning: Removing unnecessary neurons or layers that contribute little to the model’s output.
- Model Distillation: Training a smaller "student" model to mimic a larger "teacher" model, often with similar performance but faster execution.
- Hardware-Specific Optimization: Leveraging GPUs, TPUs, or specialized chips (e.g., NVIDIA Tensor Cores) for accelerated inference.
#
- Containerization To ensure consistency across environments, models are often packaged into containers using tools like Docker. A container encapsulates the model, its dependencies (e.g., Python libraries, runtime environments), and the inference logic into a single, portable unit. A typical Dockerfile for an AI model might include: dockerfile FROM python:3.9-slim WORKDIR /app COPY requirements.txt . RUN pip install -r requirements.txt COPY model /app/model COPY app.py . CMD ["python", "app.py"] This ensures that the model runs identically whether deployed on a local server, cloud instance, or edge device.
#
- Deployment Infrastructure The choice of deployment infrastructure depends on factors such as latency requirements, cost, scalability needs, and data sensitivity. Common deployment models include:
- Cloud Deployment: Using managed services like AWS SageMaker, Google Vertex AI, or Azure Machine Learning to deploy models with built-in scalability, monitoring, and security.
- On-Premise Deployment: Hosting models on internal servers or data centers, often for compliance or data privacy reasons.
- Edge Deployment: Running models on local devices (e.g., smartphones, IoT sensors) to reduce latency and enable offline operation.
- Hybrid Deployment: Combining cloud and edge environments to balance performance and cost.
#
- API Development and Integration To make the model accessible to applications, an Application Programming Interface (API) is typically created. This allows users or systems to send input data and receive predictions via HTTP requests. Common frameworks for building AI APIs include:
- FastAPI: A modern, high-performance web framework for building APIs with automatic documentation (Swagger/OpenAPI).
- Flask: A lightweight framework suitable for smaller-scale deployments.
- TensorFlow Serving: A dedicated serving system for TensorFlow models, optimized for high-throughput inference. Example FastAPI endpoint: python from fastapi import FastAPI import numpy as np import tensorflow as tf app = FastAPI() model = tf.keras.models.load_model("model.h5") @app.post("/predict") def predict(data: list): input_data = np.array(data) prediction = model.predict(input_data) return "prediction": prediction.tolist()
#
- Scaling and Load Balancing In production, models must handle varying levels of traffic. Scaling strategies include:
- Horizontal Scaling: Deploying multiple instances of the model behind a load balancer (e.g., using Kubernetes or AWS Elastic Load Balancer).
- Auto-scaling: Automatically adjusting the number of instances based on demand (e.g., using AWS Auto Scaling or Kubernetes Horizontal Pod Autoscaler).
- Batch Processing: For non-real-time applications, models can process data in batches to optimize resource usage.
#
- Monitoring and Maintenance Once deployed, continuous monitoring is essential to detect issues such as:
- Model Drift: Changes in input data distribution over time that degrade model performance.
- Performance Degradation: Increased latency or reduced accuracy due to resource constraints or software bugs.
- Security Vulnerabilities: Exploitation of API endpoints or data leaks. Tools like Prometheus, Grafana, and MLflow help track model performance, while logging systems (e.g., ELK Stack) capture errors and anomalies. Regular retraining and versioning ensure the model remains up-to-date and aligned with business goals.
#
- Security and Compliance Security is a critical aspect of AI deployment, especially when handling sensitive data. Key considerations include:
- Data Encryption: Encrypting data in transit (TLS/SSL) and at rest.
- Access Control: Implementing role-based access control (RBAC) and API authentication (e.g., OAuth2, API keys).
- Compliance: Adhering to regulations such as GDPR, HIPAA, or CCPA, particularly in healthcare and finance.
- Input Validation: Protecting against adversarial attacks (e.g., data poisoning) by validating and sanitizing input data.
#Important Facts
- Model Drift is Inevitable: Real-world data changes over time, causing model performance to degrade. Regular monitoring and retraining are necessary to maintain accuracy.
- Latency Matters: In applications like autonomous driving or real-time fraud detection, even milliseconds of delay can have significant consequences.
- Not All Models Are Equal: Deep learning models often require GPUs for fast inference, while simpler models (e.g., linear regression) can run efficiently on CPUs.
- Cost Can Be High: Cloud-based AI deployments can incur significant costs, especially for large-scale or high-frequency inference. Cost optimization strategies (e.g., spot instances, model quantization) are essential.
- Edge AI is Growing: The global edge AI market is projected to reach $1.2 trillion by 2030, driven by the need for low-latency, privacy-preserving applications.
- MLOps is the Future: Organizations that integrate MLOps practices see a 30–50% reduction in time-to-deployment and improved model reliability.
#Timeline
- Foundational ideas
Core concepts and early methods shape How to Deploy an AI Model.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does How to Deploy an AI Model cover?
Explains how to deploy an ai model, including the main process, tools, examples, risks, and practical implementation steps.
Why is How to Deploy an AI Model important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Deploy, AI, Model before using the ideas in real projects.
#References
- How to Deploy an AI Model terminology and background research
- How to Deploy an AI Model use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Deploy case studies, benchmarks, and current industry analysis

Comments
No comments yet. Start the discussion with a useful note.