#Short Answer
Explains What Is a BERT Model, including the core definition, how it works, practical examples, and limitations.
#Infobox
#Overview
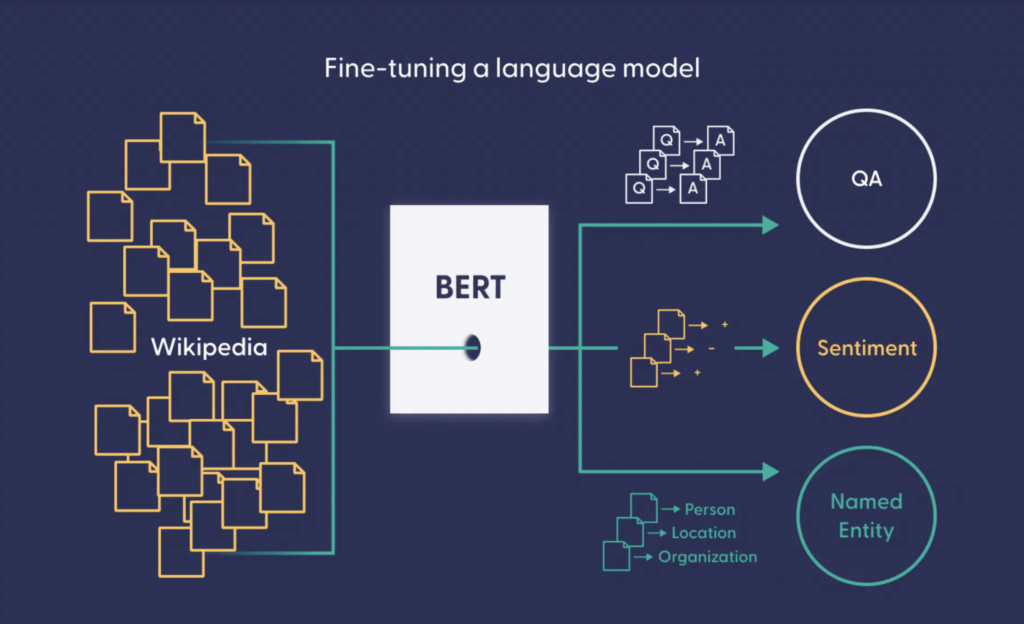
BERT is a groundbreaking pre-trained language model designed to improve the understanding of human language by machines. Unlike traditional models that read text sequentially (left-to-right or right-to-left), BERT processes text in a bidirectional manner, allowing it to capture deeper contextual relationships between words. This capability makes BERT highly effective for a wide range of NLP tasks, including sentiment analysis, machine translation, and information retrieval. The model is built on the Transformer architecture, which relies on self-attention mechanisms to weigh the importance of each word in a sentence relative to others. BERT’s pre-training involves two key tasks:
- Masked Language Modeling (MLM): Random words in a sentence are masked, and the model predicts them based on context.
- Next Sentence Prediction (NSP): The model determines whether two sentences follow each other logically. These pre-training tasks enable BERT to learn general language patterns, which can then be fine-tuned for specific applications with minimal additional training data.
#History / Background
#Origins and Development BERT was introduced by Jacob Devlin and colleagues at Google AI in the paper "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" (2018). The research built upon earlier work in transfer learning and transformer models, particularly the Transformer architecture introduced by Vaswani et al. in 2017. Before BERT, most NLP models used unidirectional approaches (e.g., left-to-right or right-to-left) or shallow bidirectional methods like ELMo (Embeddings from Language Models). These limitations hindered the model’s ability to fully grasp the nuances of language, such as polysemy (words with multiple meanings) or long-range dependencies.
#Milestones
- 2017: The Transformer architecture is introduced, revolutionizing NLP with its self-attention mechanism.
- 2018: Google releases BERT, achieving state-of-the-art results on multiple NLP benchmarks, including GLUE (General Language Understanding Evaluation) and SQuAD (Stanford Question Answering Dataset).
- 2019: BERT is integrated into Google Search, improving the relevance of search results by better understanding user queries.
- 2020s: Variants of BERT, such as RoBERTa, ALBERT, and DistilBERT, are developed to optimize performance and efficiency.
#How It Works
#Core Architecture BERT is based on the Transformer encoder, which consists of multiple layers of self-attention mechanisms and feed-forward neural networks. The model processes input text in the following steps:
- Tokenization: - Input text is split into tokens (words or subword units using WordPiece tokenization). - Special tokens are added: -
[CLS](Classification token) for sentence-level tasks. -[SEP](Separator token) to distinguish sentences. -[MASK]to replace masked words during pre-training. - Embedding Layer: - Each token is converted into a 3072-dimensional embedding combining:
- Token embeddings (word representations).
- Segment embeddings (to distinguish sentences).
- Position embeddings (to retain word order).
- Transformer Encoder: - The embeddings are passed through multiple Transformer layers, each containing:
- Multi-Head Attention: Allows the model to focus on different parts of the input simultaneously.
- Feed-Forward Networks: Apply non-linear transformations.
- Layer Normalization: Stabilizes training.
- Pre-Training Tasks:
- Masked Language Modeling (MLM): 15% of tokens are randomly masked, and the model predicts them.
- Next Sentence Prediction (NSP): The model determines if two sentences are consecutive.
- Fine-Tuning: - After pre-training, BERT is fine-tuned on specific tasks (e.g., sentiment analysis) by adding a task-specific output layer (e.g., a classifier head).
#Example For the sentence "The cat sat on the mat", BERT can predict the masked word "sat" by analyzing the surrounding context ("The cat [MASK] on the mat").
#Important Facts
- Bidirectional Context: Unlike earlier models, BERT reads text in both directions, capturing deeper semantic relationships.
- Transfer Learning: Pre-trained on large corpora, BERT can be fine-tuned for specific tasks with minimal data.
- State-of-the-Art Performance: Achieved top results on benchmarks like GLUE, SQuAD, and SWAG.
- Efficiency: BERT-Large has 340M parameters, making it computationally intensive but highly accurate.
- Multilingual BERT: Supports 104 languages, enabling cross-lingual applications.
- Applications:
- Search Engines: Improves query understanding (e.g., Google Search).
- Chatbots: Enhances conversational AI by better context comprehension.
- Healthcare: Assists in medical text analysis and drug discovery.
- Finance: Analyzes earnings reports and market sentiment.
#Timeline
- Foundational ideas
Core concepts and early methods shape What Is a BERT Model?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does What Is a BERT Model? cover?
Explains What Is a BERT Model, including the core definition, how it works, practical examples, and limitations.
Why is What Is a BERT Model? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as BERT, Model, AI before using the ideas in real projects.
#References
- What Is a BERT Model? terminology and background research
- What Is a BERT Model? use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- BERT case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.