#Short Answer
Covers understanding computer vision: a comprehensive guide, including core concepts, practical examples, benefits, limitations, and risks in Computer Vision.
#Infobox
#Overview
Computer vision is a multidisciplinary field that bridges computer science, mathematics, and cognitive science to enable machines to "see" and interpret visual information. Unlike traditional image processing, which focuses on manipulating pixel data, computer vision aims to derive high-level understanding from visual inputs, mimicking human visual perception. The primary goal of computer vision is to automate tasks that require visual comprehension, such as identifying objects, detecting anomalies, or navigating environments. This technology powers applications ranging from smartphone facial recognition to advanced medical diagnostics and self-driving cars. By combining algorithms, data, and computational power, computer vision systems can process vast amounts of visual data with speed and accuracy that surpass human capabilities in many domains. Key components of computer vision include:
- Image Acquisition: Capturing visual data via cameras or sensors.
- Preprocessing: Enhancing image quality (e.g., noise reduction, normalization).
- Feature Extraction: Identifying patterns, edges, or textures.
- Object Recognition: Classifying objects within an image.
- Scene Understanding: Interpreting the context of a visual scene.
#History / Background
#Early Foundations (1950s–1960s)
The origins of computer vision trace back to the 1950s and 1960s, when researchers began exploring ways to automate visual tasks. Early work focused on pattern recognition, particularly in optical character recognition (OCR) and simple image analysis. In 1959, Lawrence Roberts developed a program to derive 3D models from 2D images, laying the groundwork for 3D reconstruction in computer vision.
#The 1970s–1980s: Structural and Algorithmic Advances During this period, computer vision research shifted toward structural analysis, where images were broken down into geometric primitives (e.g., edges, lines, surfaces). David Marr’s seminal work, Vision: A Computational Investigation into the Human Representation and Processing of Visual Information (1982), proposed a computational theory of vision, emphasizing the importance of representation and processing in visual perception. Key developments included:
- Edge detection algorithms (e.g., Sobel, Canny filters).
- Shape-from-shading techniques.
- Early machine learning approaches like the Perceptron (Frank Rosenblatt, 1958).
#The 1990s–2000s: Statistical and Machine Learning Integration The 1990s saw the rise of statistical methods and machine learning in computer vision. Researchers began using support vector machines (SVMs) and principal component analysis (PCA) for tasks like face recognition and object detection. The PASCAL Visual Object Classes (VOC) Challenge (2005) became a benchmark for evaluating object detection algorithms.
#The 2010s: The Deep Learning Revolution The introduction of deep learning, particularly convolutional neural networks (CNNs), revolutionized computer vision. AlexNet (2012), developed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton, won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) by a significant margin, demonstrating the superiority of deep learning over traditional methods. Key milestones include:
- Region-based CNNs (R-CNNs) (2014) for object detection.
- Generative Adversarial Networks (GANs) (2014) for image synthesis.
- Transformer-based models (e.g., Vision Transformers, 2020) for improved performance.
#Modern Era
(2020s–Present)
Today, computer vision is integral to autonomous systems, healthcare diagnostics, augmented reality (AR), and industrial automation. Advances in neural radiance fields (NeRF) and diffusion models are pushing the boundaries of 3D reconstruction and generative AI. Ethical considerations, such as bias in facial recognition and privacy concerns, have also become critical areas of research.
#How It Works
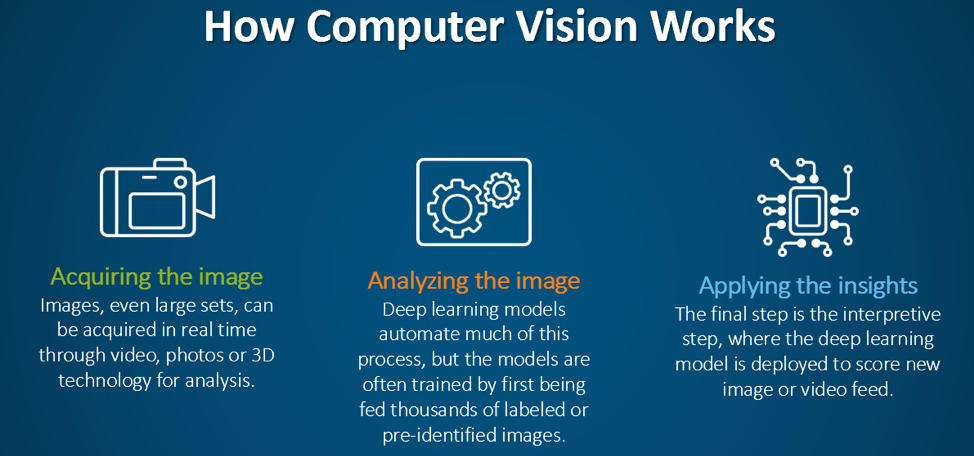
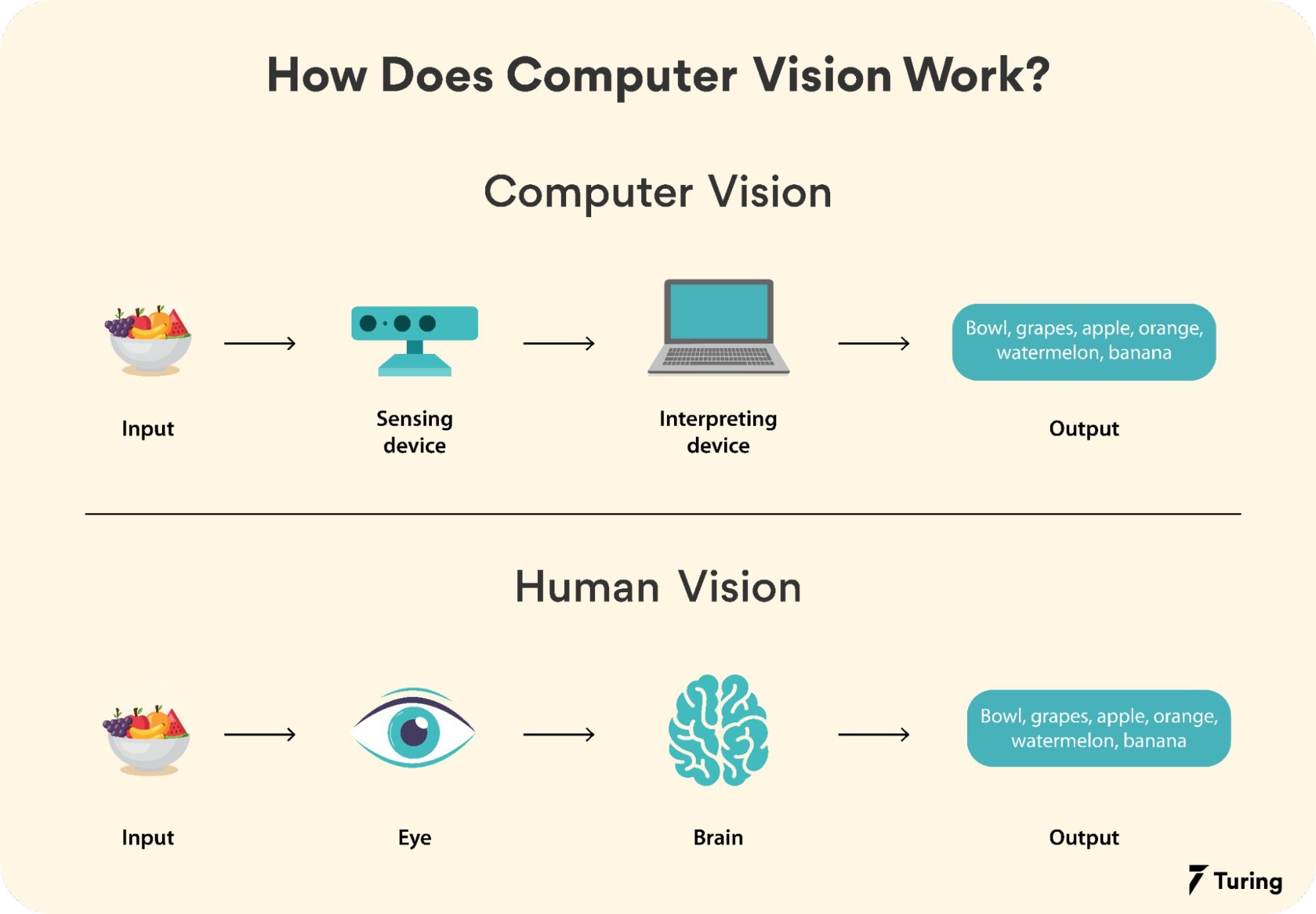
Computer vision systems follow a structured pipeline to process and interpret visual data. The process can be divided into several key stages:
#1. Image Acquisition Visual data is captured using cameras, LiDAR, or other sensors. The quality of input data significantly impacts the system’s performance. Common formats include:
- RGB images (standard color images).
- Depth maps (3D information).
- Infrared or thermal images (for specialized applications).
#2. Preprocessing Raw image data often requires enhancement to improve analysis. Preprocessing techniques include:
- Noise reduction (e.g., Gaussian blur, median filtering).
- Normalization (scaling pixel values to a standard range).
- Geometric transformations (e.g., rotation, scaling, cropping).
- Color space conversion (e.g., RGB to grayscale, HSV).
#3. Feature Extraction Features are distinctive patterns or attributes that help identify objects or structures in an image. Traditional methods include:
- Edge detection (Canny, Sobel operators).
- Corner detection (Harris corner detector).
- Texture analysis (Local Binary Patterns, Gabor filters). Modern systems rely on deep learning-based feature extraction, where neural networks automatically learn hierarchical representations of data.
#4. Object Detection and Recognition This stage involves identifying and classifying objects within an image. Approaches include:
- Template matching: Comparing image patches to predefined templates.
- Bag-of-Visual-Words (BoVW): Representing images as collections of visual "words."
- Deep learning models:
- CNNs (e.g., ResNet, VGG) for classification.
- Region-based methods (e.g., Faster R-CNN, YOLO) for detection.
- Segmentation models (e.g., U-Net, Mask R-CNN) for pixel-level labeling.
#5. Scene Understanding Beyond individual objects, computer vision systems aim to interpret the context of a scene. This involves:
- Semantic segmentation: Assigning labels to every pixel (e.g., "road," "car," "pedestrian").
- Instance segmentation: Differentiating between multiple instances of the same object.
- 3D reconstruction: Creating 3D models from 2D images (e.g., using Structure from Motion (SfM) or NeRF).
- Activity recognition: Identifying human actions or behaviors (e.g., walking, running).
#6. Decision Making and Action The final output may trigger actions, such as:
- Autonomous navigation (e.g., self-driving cars).
- Medical diagnosis (e.g., detecting tumors in X-rays).
- Industrial quality control (e.g., identifying defects in manufacturing).
- Augmented reality overlays (e.g., Pokémon GO, AR navigation).
#Important Facts
- Human vs. Machine Vision: - Humans process visual information using parallel processing in the brain, while computers rely on sequential algorithms. - Computer vision excels in speed and scalability but often lacks the contextual understanding of human vision.
- Key Challenges:
- Variability in lighting and viewpoint: Objects may appear differently under varying conditions.
- Occlusion: Objects may be partially hidden, making detection difficult.
- Real-time processing: Many applications (e.g., autonomous driving) require low-latency processing.
- Bias and fairness: Models trained on biased datasets may produce unfair or inaccurate results.
- Performance Metrics:
- Accuracy: Percentage of correct predictions.
- Precision and Recall: Trade-off between false positives and false negatives.
- Intersection over Union (IoU): Measures overlap between predicted and ground truth bounding boxes.
- Mean Average Precision (mAP): Evaluates object detection models.
- Hardware Acceleration:
- GPUs (Graphics Processing Units): Essential for training deep learning models.
- TPUs (Tensor Processing Units): Google’s custom hardware for AI workloads.
- Edge AI: Deploying lightweight models on mobile devices or IoT sensors for real-time processing.
- Ethical and Societal Impact:
- Privacy concerns: Facial recognition systems raise issues about surveillance and consent.
- Job displacement: Automation in industries like manufacturing and retail may reduce manual labor roles.
- Deepfakes and misinformation: AI-generated images/videos can be used to spread fake news or fraud.
#Timeline
- Foundational ideas
Core concepts and early methods shape Understanding Computer Vision: a Comprehensive Guide.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Understanding Computer Vision: a Comprehensive Guide cover?
Covers understanding computer vision: a comprehensive guide, including core concepts, practical examples, benefits, limitations, and risks in Computer Vision.
Why is Understanding Computer Vision: a Comprehensive Guide important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Computer Vision decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Understanding, Computer, Vision before using the ideas in real projects.
#References
- Understanding Computer Vision: a Comprehensive Guide terminology and background research
- Understanding Computer Vision: a Comprehensive Guide use cases, implementation examples, and limitations
- Computer Vision best practices, standards, and risk guidance
- Understanding case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.