
#Short Answer
Explores the future of computer vision, including emerging trends, practical impacts, risks, and important signals to watch.
#Infobox
#Overview
The future of computer vision is poised to transform how humans interact with technology, bridging the gap between digital and physical worlds. As artificial intelligence (AI) continues to evolve, computer vision is becoming more sophisticated, enabling machines to perceive and interpret visual information with near-human accuracy. This progress is driven by breakthroughs in deep learning, hardware advancements, and the proliferation of data, which collectively enhance the capabilities of vision systems. Computer vision is already integral to modern applications such as facial recognition, autonomous driving, and medical diagnostics. However, the next decade will see even greater integration into daily life, with innovations like real-time 3D reconstruction, emotion recognition, and hyper-personalized user experiences. The convergence of computer vision with other AI domains, such as natural language processing (NLP) and robotics, will further expand its potential, creating systems that can understand and respond to complex visual and contextual cues.
#History / Background
The origins of computer vision trace back to the 1960s, when researchers began exploring ways to enable machines to interpret visual data. Early work focused on simple tasks like edge detection and pattern recognition, but progress was limited by computational constraints and the lack of large datasets. The field gained momentum in the 1980s and 1990s with the development of more advanced algorithms and the advent of digital imaging. A pivotal moment arrived in the 2010s with the rise of deep learning, particularly convolutional neural networks (CNNs). The breakthrough performance of CNNs in image classification tasks, demonstrated by AlexNet in the 2012 ImageNet competition, marked a turning point. Since then, computer vision has advanced rapidly, with innovations such as generative adversarial networks (GANs), transformers, and self-supervised learning pushing the boundaries of what machines can achieve. Key milestones in the evolution of computer vision include:
- 1966: The "Summer Vision Project" at MIT, one of the first attempts to develop a system that could interpret visual scenes.
- 1980s: Introduction of edge detection algorithms like the Sobel operator and Canny edge detector.
- 2001: Viola-Jones algorithm for real-time face detection.
- 2012: AlexNet wins the ImageNet competition, demonstrating the power of deep learning for image recognition.
- 2015: Introduction of YOLO (You Only Look Once), a real-time object detection system.
- 2020s: Advances in transformer-based models like Vision Transformers (ViT) and multimodal systems like CLIP.
#How It Works
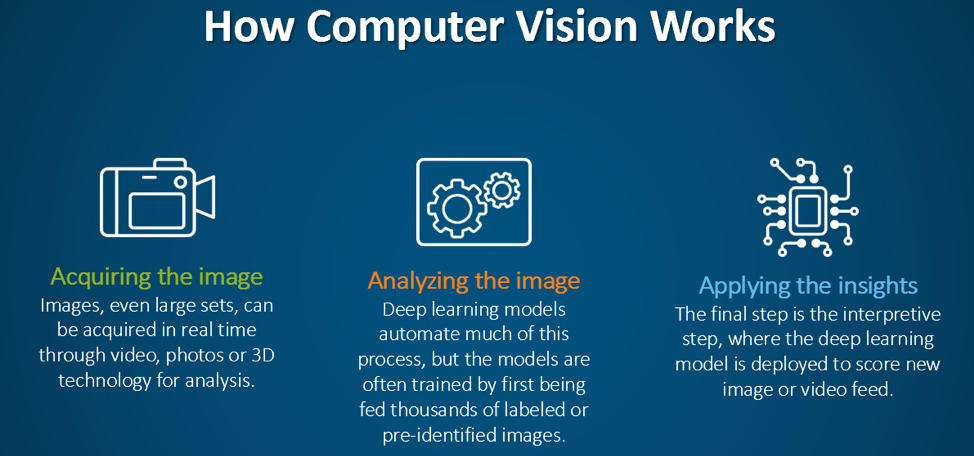
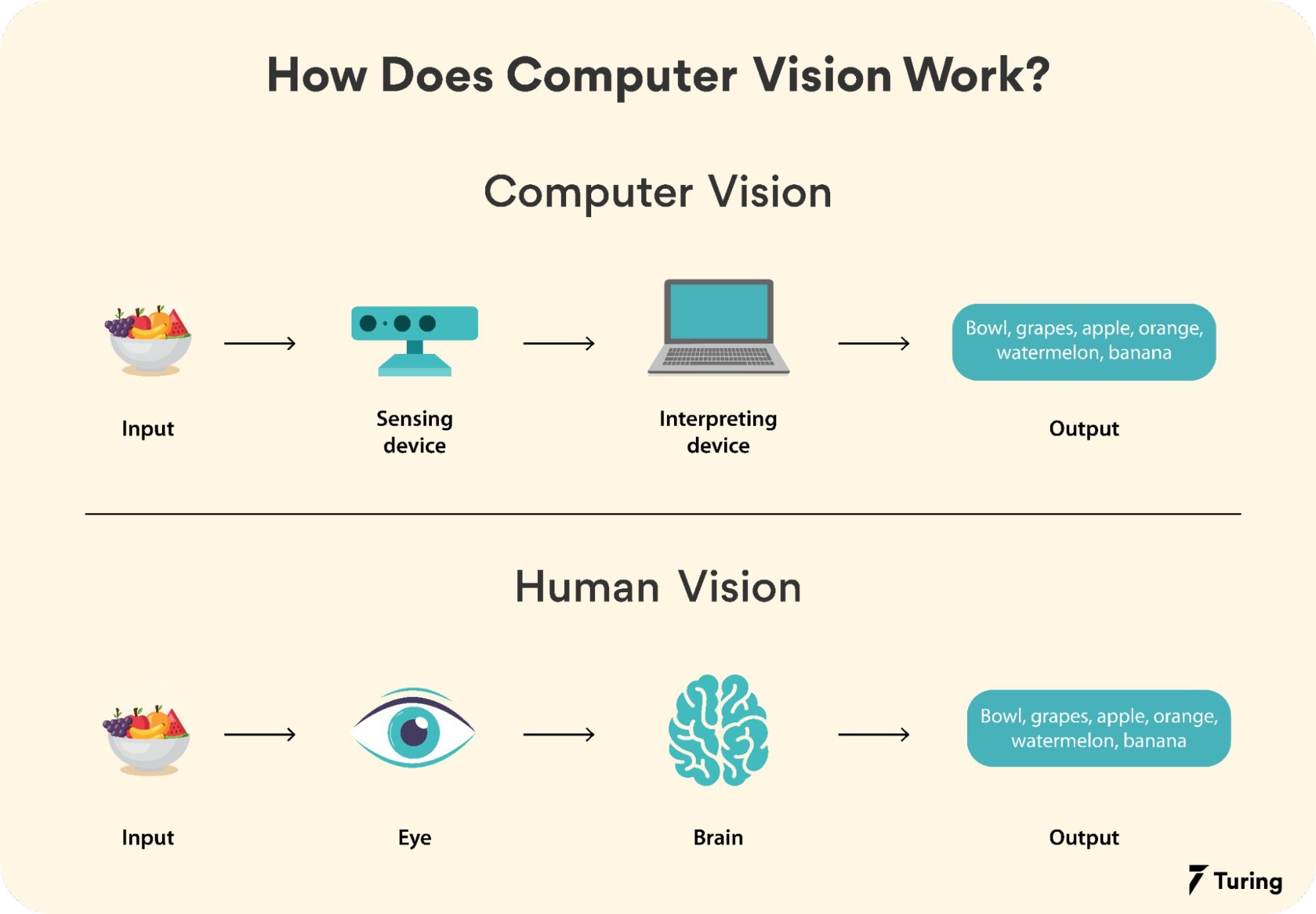
Computer vision systems rely on a combination of hardware and software to process and interpret visual data. The process typically involves several key steps:
- Image Acquisition: Capturing visual data using cameras, sensors, or other imaging devices. This data can include static images, video streams, or 3D scans.
- Preprocessing: Enhancing the quality of the input data through techniques like noise reduction, normalization, and augmentation. Preprocessing ensures that the data is suitable for analysis.
- Feature Extraction: Identifying and extracting relevant features from the input data. Traditional methods include edge detection, texture analysis, and color histograms, while modern approaches use deep learning models to automatically learn hierarchical features.
- Model Training: Using labeled datasets to train machine learning models. In supervised learning, models are trained on annotated data to recognize patterns and make predictions. Unsupervised and self-supervised learning techniques are also employed to leverage unlabeled data.
- Inference: Applying the trained model to new, unseen data to make predictions or decisions. This step involves classifying objects, detecting anomalies, or segmenting images into meaningful regions.
- Post-Processing: Refining the output of the model to improve accuracy and usability. Techniques like non-maximum suppression (NMS) are used to filter out redundant detections in object recognition tasks.
#Key Technologies
- Convolutional Neural Networks (CNNs): The backbone of modern computer vision, CNNs are designed to automatically and adaptively learn spatial hierarchies of features from input images.
- Transformers: Originally developed for natural language processing, transformers have been adapted for vision tasks, enabling models like Vision Transformers (ViT) to achieve state-of-the-art performance.
- Generative Models: GANs and diffusion models are used for tasks like image synthesis, super-resolution, and data augmentation.
- Edge AI: Deploying computer vision models on edge devices (e.g., smartphones, IoT devices) to enable real-time processing and reduce latency.
- Explainable AI (XAI): Techniques to make computer vision models more interpretable, helping users understand how decisions are made.
#Important Facts
- Accuracy: Modern computer vision systems can achieve over 99% accuracy in tasks like facial recognition and object detection, rivaling human performance in some domains.
- Speed: Real-time processing is now possible, with models capable of analyzing thousands of frames per second on high-end GPUs.
- Data Dependency: The performance of computer vision models is heavily dependent on the quality and quantity of training data. Large datasets like ImageNet, COCO, and Open Images are critical for training robust models.
- Bias and Fairness: Computer vision systems can inherit biases present in training data, leading to disparities in performance across different demographic groups. Addressing bias is a major focus of ongoing research.
- Energy Consumption: Training large computer vision models requires significant computational resources, raising concerns about environmental impact and energy efficiency.
- Regulation: Governments and organizations are increasingly implementing regulations around the use of computer vision, particularly in areas like surveillance and facial recognition.
#Timeline
- Foundational ideas
Core concepts and early methods shape The Future of Computer Vision.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does The Future of Computer Vision cover?
Explores the future of computer vision, including emerging trends, practical impacts, risks, and important signals to watch.
Why is The Future of Computer Vision important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Computer Vision decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Future, Computer, Vision before using the ideas in real projects.
#References
- The Future of Computer Vision terminology and background research
- The Future of Computer Vision use cases, implementation examples, and limitations
- Computer Vision best practices, standards, and risk guidance
- Future case studies, benchmarks, and current industry analysis

Comments
No comments yet. Start the discussion with a useful note.