#Short Answer
Covers meaning of computer vision, including core concepts, practical examples, benefits, limitations, and risks in Computer Vision.
#Infobox
#Overview
Computer vision is a multidisciplinary field that integrates computer science, mathematics, and cognitive science to enable machines to process, analyze, and derive meaningful insights from visual data. It bridges the gap between human visual perception and computational interpretation, allowing systems to perform tasks such as object detection, image segmentation, and scene reconstruction with high accuracy. At its core, computer vision aims to replicate the human ability to recognize patterns, identify objects, and understand spatial relationships within images or video streams. Unlike traditional image processing, which focuses on enhancing or transforming visual data, computer vision emphasizes interpretation and decision-making based on visual inputs. This capability is powered by advanced algorithms, machine learning models, and neural networks that can learn from vast datasets to generalize and make predictions. The applications of computer vision span across numerous industries, including healthcare, automotive, security, agriculture, and entertainment. For instance, in healthcare, it assists in diagnosing diseases from medical scans, while in autonomous vehicles, it enables real-time navigation by detecting pedestrians, road signs, and obstacles. The versatility of computer vision makes it one of the most transformative technologies of the 21st century.
#History / Background
The origins of computer vision can be traced back to the 1960s, when researchers began exploring ways to enable computers to "see" and interpret visual data. One of the earliest breakthroughs occurred in 1966, when Seymour Papert and Marvin Minsky at MIT initiated a project to develop a system that could describe the contents of a photograph. This project, though rudimentary, laid the foundation for future research in the field. In the 1970s, David Marr, a neuroscientist and computer scientist, proposed a computational theory of vision that emphasized the importance of understanding the human visual system to design better algorithms. His work, published in Vision: A Computational Investigation into the Human Representation and Processing of Visual Information (1982), became a seminal reference for computer vision researchers. The 1980s and 1990s saw significant advancements with the introduction of techniques such as edge detection, feature extraction, and 3D reconstruction. Takeo Kanade, a pioneer in the field, developed early computer vision systems for robotics and autonomous navigation. Meanwhile, the advent of the internet and digital cameras led to an explosion of visual data, creating opportunities for machine learning approaches to be applied to computer vision tasks. The 2000s marked a turning point with the rise of deep learning, particularly convolutional neural networks (CNNs). In 2012, Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton demonstrated the power of CNNs by winning the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) with a model that significantly outperformed traditional methods. This breakthrough sparked a revolution in computer vision, leading to state-of-the-art models such as ResNet, YOLO, and Vision Transformers (ViT). Today, computer vision continues to evolve rapidly, driven by advances in hardware (e.g., GPUs, TPUs), algorithms, and data availability. It has become an integral part of modern technology, powering applications from facial recognition in smartphones to real-time object detection in drones.
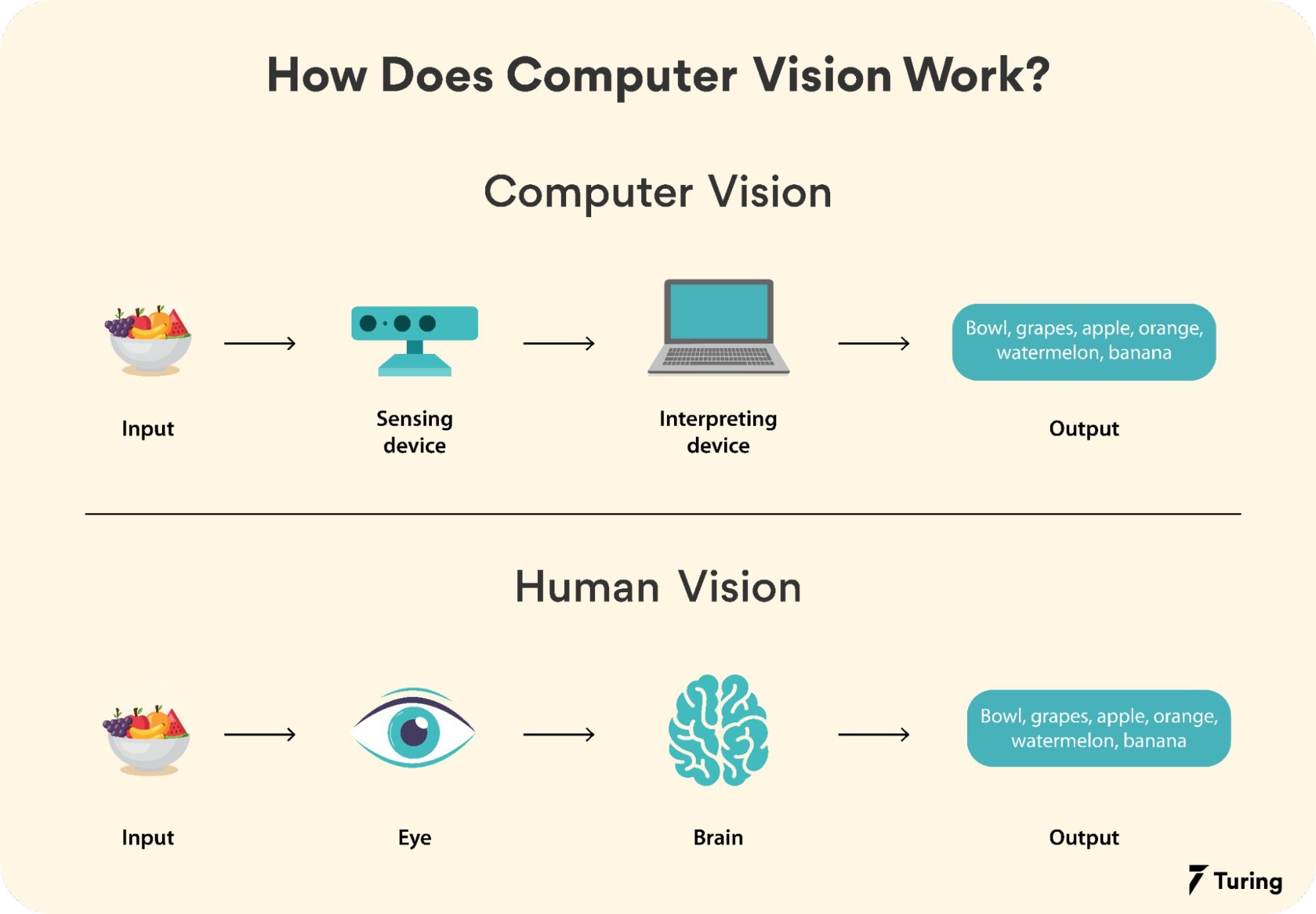
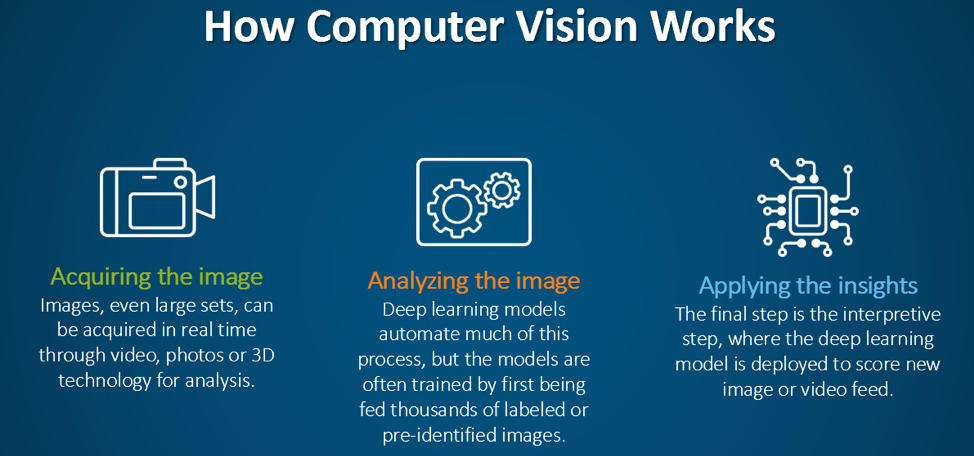
#How It Works
Computer vision systems operate through a series of interconnected steps, each designed to process visual data and extract meaningful information. The process can be broadly divided into several key stages:
#1. Image Acquisition The first step involves capturing visual data using devices such as cameras, sensors, or scanners. The quality and type of input (e.g., RGB images, infrared, depth maps) depend on the application. For example, autonomous vehicles use a combination of cameras, LiDAR, and radar to gather comprehensive environmental data.
#2. Preprocessing Raw visual data often contains noise, distortions, or irrelevant information. Preprocessing techniques such as noise reduction, normalization, and contrast enhancement are applied to improve the quality of the input. Common methods include:
- Gaussian blur to reduce noise.
- Histogram equalization to improve contrast.
- Edge detection (e.g., using the Sobel or Canny operator) to highlight boundaries.
#3. Feature Extraction Features are distinctive attributes of an image that help in identifying objects or patterns. Traditional methods rely on handcrafted features such as:
- SIFT (Scale-Invariant Feature Transform) for detecting keypoints.
- HOG (Histogram of Oriented Gradients) for object detection.
- Haar cascades for face detection. Modern systems, however, leverage deep learning to automatically extract hierarchical features from raw pixels. Convolutional neural networks (CNNs) use layers of filters to detect edges, textures, and complex patterns in a hierarchical manner.
#4. Segmentation Image segmentation divides an image into meaningful regions or objects. Techniques include:
- Semantic segmentation, which assigns a class label to each pixel (e.g., "car," "road").
- Instance segmentation, which distinguishes between individual objects of the same class (e.g., two separate cars).
- Clustering methods such as k-means or graph-based approaches.
#5. Recognition and Classification Once features are extracted, the system classifies the image or identifies objects within it. This step often involves:
- Object detection, which locates and labels objects in an image (e.g., using YOLO or Faster R-CNN).
- Image classification, which assigns a single label to an entire image (e.g., "cat," "dog").
- Facial recognition, which identifies or verifies individuals based on facial features.
#6. 3D Reconstruction In applications such as robotics or augmented reality, computer vision systems reconstruct 3D models from 2D images. Techniques include:
- Stereo vision, which uses multiple cameras to estimate depth.
- Structure from Motion (SfM), which reconstructs 3D scenes from a series of 2D images.
- LiDAR-based reconstruction, which uses laser scans to create detailed 3D maps.
#7. Decision Making The final step involves using the extracted information to make decisions or take actions. For example: - An autonomous vehicle may use object detection to decide when to brake or change lanes. - A medical imaging system may classify a tumor as benign or malignant based on scan analysis.
#Important Facts
- Accuracy: Modern computer vision systems, particularly those using deep learning, achieve accuracy rates exceeding 99% in tasks such as image classification (e.g., ImageNet benchmarks).
- Speed: Real-time computer vision applications, such as those in autonomous vehicles, process visual data at speeds of up to 30 frames per second (fps) or higher.
- Data Requirements: Training robust computer vision models often requires large datasets. For example, the ImageNet dataset contains over 14 million labeled images across 20,000 categories.
- Hardware: Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs) are essential for training and deploying deep learning models due to their parallel processing capabilities.
- Ethical Concerns: Computer vision raises ethical issues such as privacy (e.g., facial recognition), bias in algorithms, and misuse in surveillance.
- Energy Consumption: Training large-scale models can consume significant computational resources, leading to concerns about environmental impact.
- Open-Source Tools: Popular frameworks like OpenCV, TensorFlow, and PyTorch have democratized access to computer vision tools, enabling researchers and developers worldwide to build and deploy models.
#Timeline
- Foundational ideas
Core concepts and early methods shape Meaning of Computer Vision.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Meaning of Computer Vision cover?
Covers meaning of computer vision, including core concepts, practical examples, benefits, limitations, and risks in Computer Vision.
Why is Meaning of Computer Vision important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Computer Vision decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Meaning, Computer, Vision before using the ideas in real projects.
#References
- Meaning of Computer Vision terminology and background research
- Meaning of Computer Vision use cases, implementation examples, and limitations
- Computer Vision best practices, standards, and risk guidance
- Meaning case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.