#Short Answer
Traces the rise of neural networks: a historical perspective, highlighting major milestones, context, examples, and future implications.
#Infobox
#History / Background
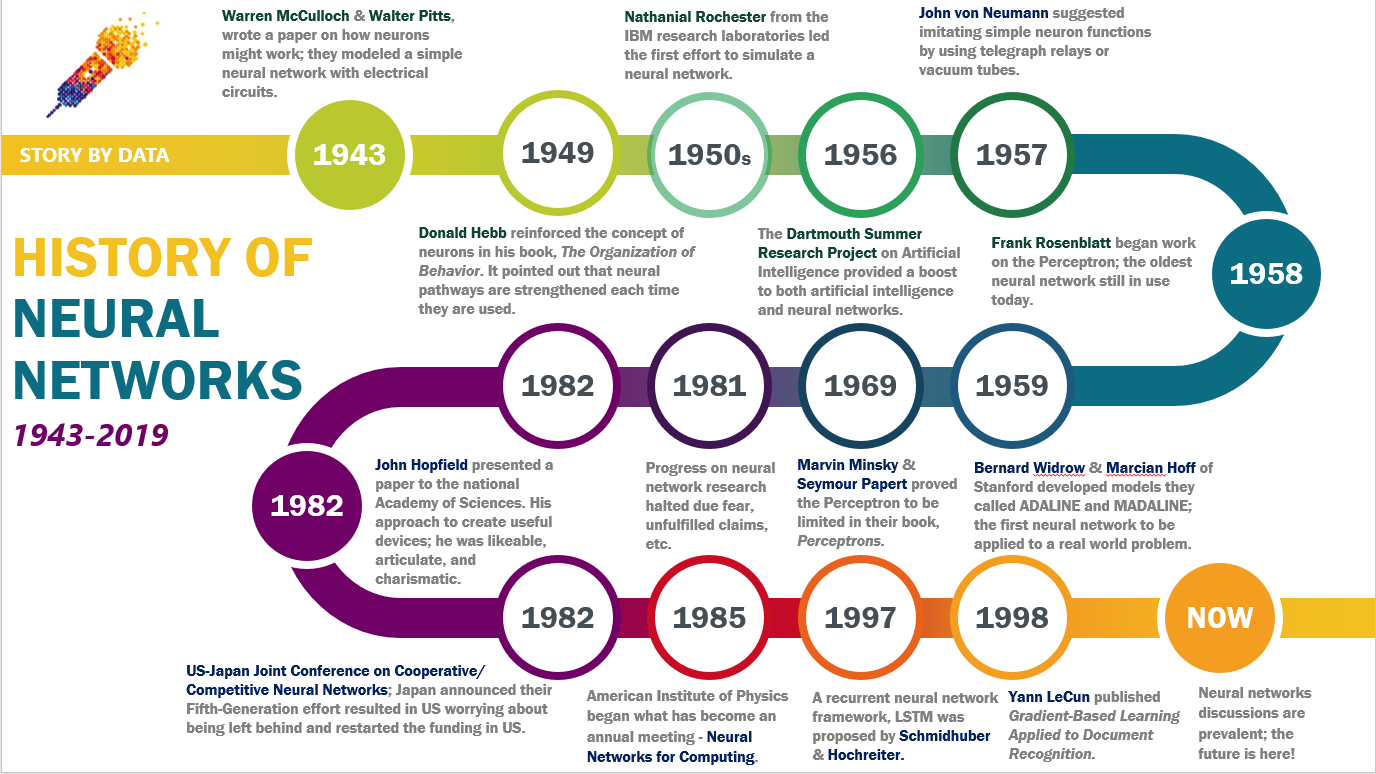
Early Foundations (1940s–1960s) The conceptual origins of neural networks trace back to the 1940s, when researchers began exploring the idea of simulating neural processes computationally. In 1943, neurophysiologist Warren McCulloch and mathematician Walter Pitts published a seminal paper introducing the McCulloch-Pitts neuron, a simplified model of a biological neuron that could perform logical operations. This work laid the groundwork for artificial intelligence by demonstrating that neural-like structures could compute complex functions. The next major milestone came in 1958 with the invention of the Perceptron by Frank Rosenblatt. The Perceptron was the first trainable neural network, capable of learning from data through a process called supervised learning. Rosenblatt’s work demonstrated that a single-layer neural network could classify linearly separable data, sparking optimism about the potential of artificial intelligence. However, limitations in computational power and the Perceptron’s inability to solve non-linear problems led to a decline in interest during the 1970s, a period now known as the "AI Winter."
Revival and Challenges (1980s–1990s) The 1980s witnessed a resurgence of interest in neural networks, fueled by the development of backpropagation, an algorithm that enabled multi-layer neural networks to learn from errors. Introduced independently by several researchers, including David Rumelhart, Geoffrey Hinton, and Ronald Williams, backpropagation addressed the limitations of single-layer networks by allowing information to flow backward through the network to adjust weights and improve accuracy. During this period, Hopfield networks (1982) and Boltzmann machines (1985) emerged as significant contributions. Hopfield networks, proposed by John Hopfield, demonstrated the ability to store and retrieve patterns, while Boltzmann machines introduced stochastic (probabilistic) elements to neural networks, enabling them to model complex distributions. Despite these advances, neural networks faced stiff competition from symbolic AI approaches, which dominated the field until the late 1990s.
The Deep Learning Revolution (2000s–Present) The 21st century marked a paradigm shift in neural network research, driven by three key factors:
- Increased Computational Power: The advent of Graphics Processing Units (GPUs) enabled the training of large-scale neural networks.
- Big Data: The proliferation of digital data provided the necessary fuel for training complex models.
- Algorithmic Innovations: Breakthroughs such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs) expanded the capabilities of neural networks. In 2012, a team led by Geoffrey Hinton demonstrated the power of deep learning by winning the ImageNet Large Scale Visual Recognition Challenge with a CNN, achieving unprecedented accuracy in image classification. This event catalyzed widespread adoption of deep learning across industries, leading to advancements in:
- Computer Vision: Object detection, facial recognition, and medical imaging.
- Natural Language Processing (NLP): Machine translation, sentiment analysis, and chatbots.
- Reinforcement Learning: Autonomous vehicles, robotics, and game-playing AI (e.g., AlphaGo). Today, neural networks continue to evolve, with architectures like transformers (introduced in 2017) revolutionizing NLP and enabling the development of large language models (LLMs) such as GPT-3 and PaLM.
#How It Works
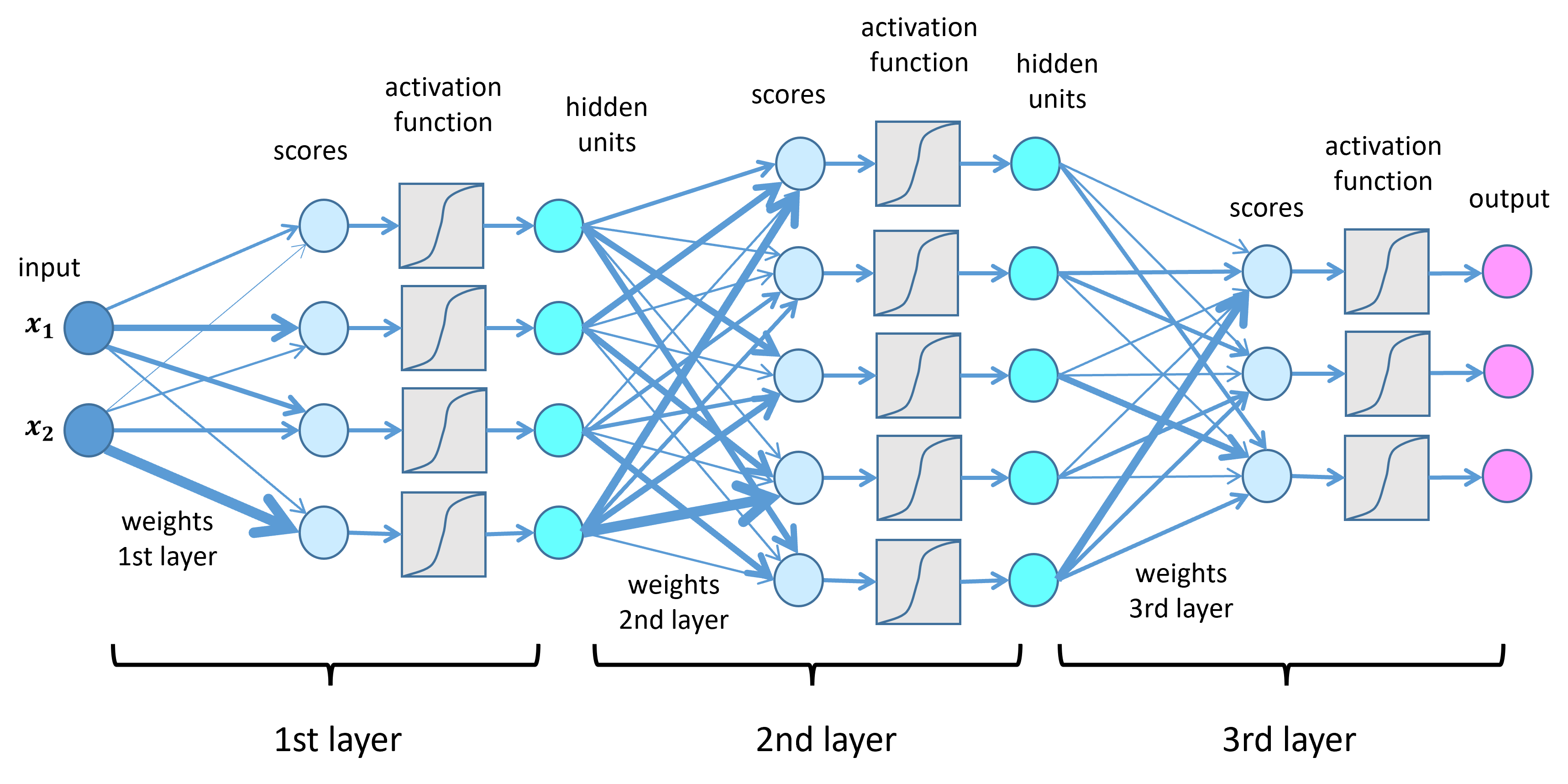
Basic Structure A neural network consists of three primary components:
- Input Layer: Receives raw data (e.g., pixels in an image, words in a sentence).
- Hidden Layers: Intermediate layers that transform input data through weighted connections. These layers apply activation functions (e.g., ReLU, sigmoid) to introduce non-linearity.
- Output Layer: Produces the final prediction or classification.
Key Concepts
- Neurons (Nodes): Basic units that receive inputs, apply weights, and pass outputs through activation functions.
- Weights and Biases: Parameters adjusted during training to minimize prediction errors.
- Activation Functions: Non-linear functions (e.g., ReLU, tanh) that determine whether a neuron should "fire."
- Loss Function: Measures the difference between predicted and actual outputs (e.g., mean squared error, cross-entropy loss).
- Optimization Algorithms: Techniques like gradient descent and Adam that update weights to minimize loss.
Training Process
- Forward Propagation: Input data is passed through the network to generate predictions.
- Loss Calculation: The difference between predictions and true labels is computed.
- Backpropagation: The gradient of the loss function is calculated with respect to each weight, and weights are updated to reduce error.
- Iteration: The process repeats over multiple epochs until the model achieves satisfactory performance.
Types of Neural Networks
- Feedforward Neural Networks (FNNs): Data flows in one direction, from input to output.
- Convolutional Neural Networks (CNNs): Specialized for grid-like data (e.g., images), using convolutional layers to extract features.
- Recurrent Neural Networks (RNNs): Designed for sequential data (e.g., time series, text), with loops to maintain memory.
- Generative Adversarial Networks (GANs): Comprise two networks (generator and discriminator) that compete to produce realistic data.
- Transformers: Use self-attention mechanisms to process sequential data efficiently, powering modern NLP models.
#Important Facts
- Universal Approximation Theorem: A neural network with at least one hidden layer can approximate any continuous function, given sufficient neurons and proper training.
- Overfitting: Occurs when a model learns noise in the training data, leading to poor generalization. Techniques like dropout and regularization mitigate this issue.
- Transfer Learning: Pre-trained models (e.g., ResNet, BERT) can be fine-tuned for specific tasks, reducing the need for large datasets.
- Explainability: Neural networks are often criticized for being "black boxes." Efforts like SHAP values and LIME aim to interpret model decisions.
- Ethical Concerns: Bias in training data can lead to discriminatory outcomes, necessitating fairness-aware algorithms and diverse datasets.
#Timeline
- Foundational ideas
Core concepts and early methods shape The Rise of Neural Networks: a Historical Perspective.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does The Rise of Neural Networks: a Historical Perspective cover?
Traces the rise of neural networks: a historical perspective, highlighting major milestones, context, examples, and future implications.
Why is The Rise of Neural Networks: a Historical Perspective important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Rise, Neural, Networks before using the ideas in real projects.
#References
- The Rise of Neural Networks: a Historical Perspective terminology and background research
- The Rise of Neural Networks: a Historical Perspective use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Rise case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.