#Short Answer
Covers neural networks for beginners: a friendly introduction, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
#Infobox
#Overview
Neural Networks for Beginners: An Easy-to-Follow Introduction to serves as an introductory guide to the fundamental principles of artificial neural networks (ANNs). Designed for individuals with little to no prior knowledge of machine learning, the resource breaks down complex topics into digestible explanations, making it accessible to a broad audience. The book covers core concepts such as neurons, layers, activation functions, and training processes, while also exploring real-world applications in fields like image recognition, natural language processing, and predictive analytics. The term "neural network" originates from its inspiration by biological neural networks in the human brain, where interconnected neurons process and transmit information. In computing, ANNs simulate this behavior using mathematical models to recognize patterns, classify data, and make decisions. This introductory material is particularly valuable for students, professionals, and hobbyists seeking to build a solid foundation in machine learning before advancing to more specialized topics.
#History / Background
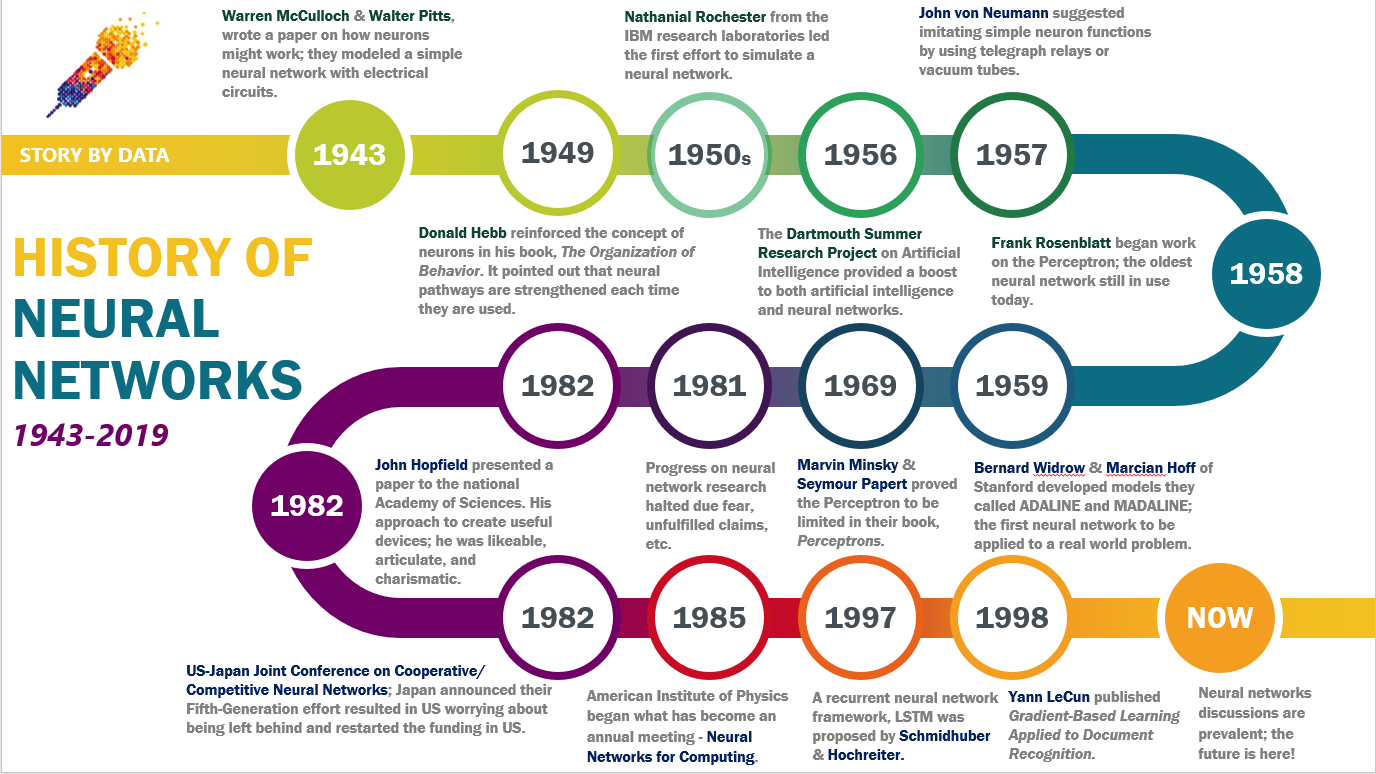
#Origins of Neural Networks The concept of neural networks dates back to the 1940s, with early work by Warren McCulloch and Walter Pitts, who proposed a simplified model of the neuron in 1943. Their paper, A Logical Calculus of Ideas Immanent in Nervous Activity, laid the groundwork for artificial neural networks by modeling binary logic using artificial neurons. In 1958, Frank Rosenblatt developed the Perceptron, the first functional neural network model capable of learning from data. The Perceptron was a single-layer network designed for binary classification tasks, such as distinguishing between two types of patterns. However, its limitations became apparent when it was proven that single-layer networks could not solve problems involving non-linear separability, such as the XOR problem.
#The AI Winter and Revival During the 1970s and 1980s, interest in neural networks waned due to funding cuts and skepticism about their capabilities—a period known as the AI Winter. Research stagnated until the mid-1980s, when Geoffrey Hinton, David Rumelhart, and Ronald Williams introduced the backpropagation algorithm, enabling multi-layer neural networks to learn effectively. This breakthrough reignited interest in the field and led to the development of deep learning, a subset of machine learning characterized by networks with multiple hidden layers.
#Modern Advancements The 2010s marked a resurgence in neural network research, fueled by advances in computing power, the availability of large datasets, and innovations like convolutional neural networks (CNNs) and recurrent neural networks (RNNs). These models achieved state-of-the-art performance in tasks such as image classification (e.g., AlexNet in 2012) and language translation (e.g., Google Translate). Today, neural networks underpin many cutting-edge technologies, including self-driving cars, virtual assistants, and recommendation systems.
#How It Works
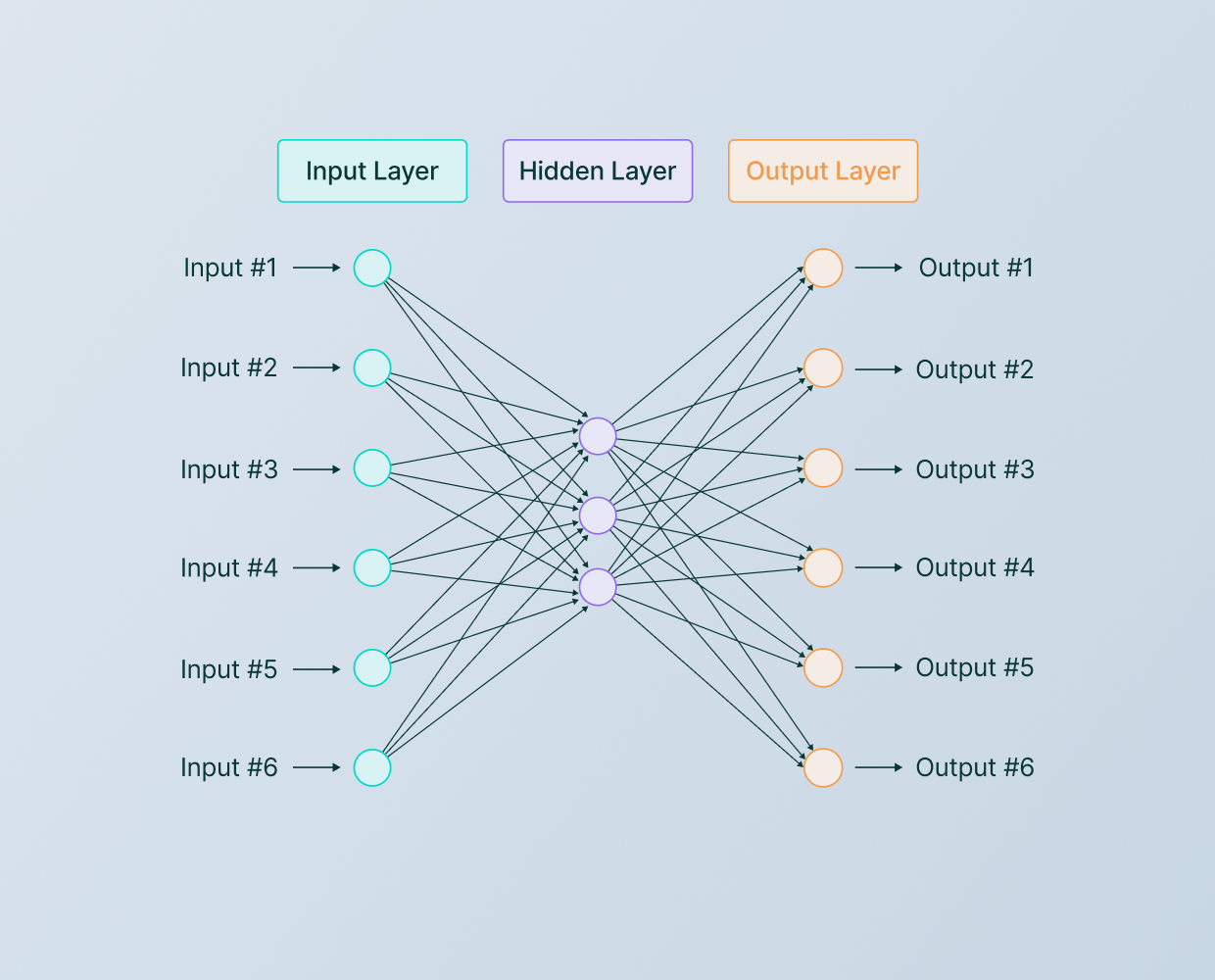
#Basic Structure of a Neural Network A neural network consists of interconnected layers of neurons (or nodes), which are organized into three primary types:
- Input Layer: Receives raw data (e.g., pixels in an image, words in a sentence) and passes it to the next layer.
- Hidden Layers: Perform computations and transformations on the input data. These layers can be dense (fully connected), convolutional, or recurrent, depending on the task.
- Output Layer: Produces the final prediction or classification (e.g., identifying an object in an image or predicting a numerical value).
#Key Components
- Neurons: Basic units that receive inputs, apply a mathematical operation (e.g., weighted sum), and pass the result through an activation function (e.g., ReLU, sigmoid).
- Weights and Biases: Parameters that the network learns during training. Weights determine the strength of connections between neurons, while biases shift the activation function.
- Activation Functions: Introduce non-linearity into the model, enabling it to learn complex patterns. Common functions include:
- Sigmoid: Outputs values between 0 and 1 (useful for binary classification).
- ReLU (Rectified Linear Unit): Outputs the input directly if positive, otherwise zero (common in hidden layers).
- Softmax: Converts outputs into probabilities (used in multi-class classification).
- Loss Function: Measures the difference between the predicted output and the actual target. Common loss functions include Mean Squared Error (MSE) for regression and Cross-Entropy Loss for classification.
- Optimizer: Adjusts the weights and biases to minimize the loss. Popular optimizers include Stochastic Gradient Descent (SGD), Adam, and RMSprop.
#Training Process
Neural networks learn through supervised learning, where they are trained on labeled data (input-output pairs). The training process involves:
- Forward Propagation: Input data is passed through the network, and predictions are generated.
- Loss Calculation: The difference between predictions and actual labels is computed using the loss function.
- Backpropagation: The gradient of the loss function is calculated with respect to each weight, and the weights are updated using the optimizer to reduce the loss.
- Iteration: The process repeats over multiple epochs (passes through the dataset) until the model achieves satisfactory performance.
#Types of Neural Networks
- Feedforward Neural Networks (FNNs): The simplest type, where data flows in one direction (input to output).
- Convolutional Neural Networks (CNNs): Specialized for grid-like data (e.g., images), using convolutional layers to detect spatial patterns.
- Recurrent Neural Networks (RNNs): Designed for sequential data (e.g., time series, text), where connections form directed cycles to retain memory.
- Generative Adversarial Networks (GANs): Consist of two networks (a generator and a discriminator) that compete to improve each other’s performance, often used for generating realistic data.
#Important Facts
- Universal Approximation Theorem: A neural network with at least one hidden layer can approximate any continuous function, given sufficient neurons and proper training.
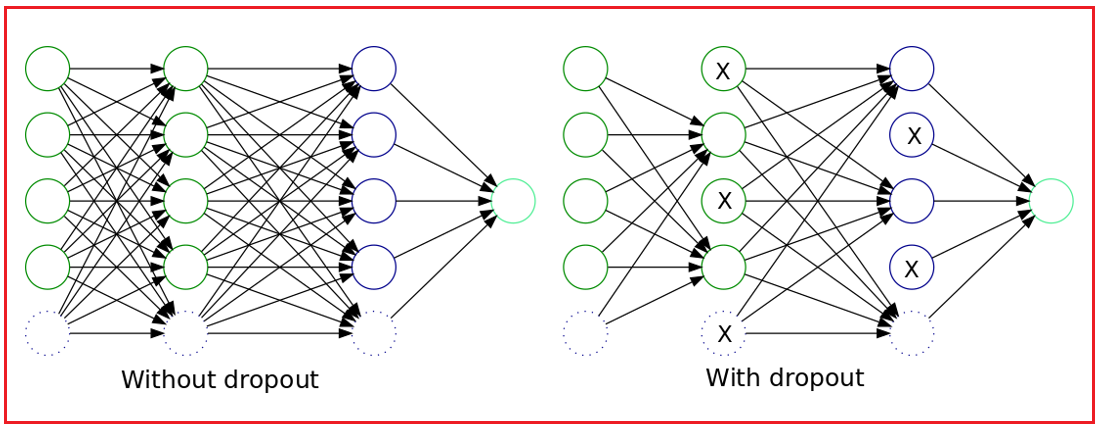
- Overfitting: Occurs when a model learns the training data too well, including noise, and performs poorly on unseen data. Techniques like regularization, dropout, and early stopping help mitigate this issue.
- Transfer Learning: A technique where a pre-trained model is fine-tuned for a new task, reducing the need for large datasets and computational resources.
- Bias-Variance Tradeoff: A fundamental concept in machine learning where reducing bias (error due to overly simple models) may increase variance (error due to overly complex models), and vice versa.
- Hardware Acceleration: Neural networks often require significant computational power. Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs) are commonly used to speed up training and inference.
#Timeline
- Foundational ideas
Core concepts and early methods shape Neural Networks for Beginners: a Friendly Introduction.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Neural Networks for Beginners: a Friendly Introduction cover?
Covers neural networks for beginners: a friendly introduction, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
Why is Neural Networks for Beginners: a Friendly Introduction important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Neural, Networks, AI before using the ideas in real projects.
#References
- Neural Networks for Beginners: a Friendly Introduction terminology and background research
- Neural Networks for Beginners: a Friendly Introduction use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Neural case studies, benchmarks, and current industry analysis

Comments
No comments yet. Start the discussion with a useful note.