
#Short Answer
Covers neural networks: pros and cons, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
#Infobox
#Overview
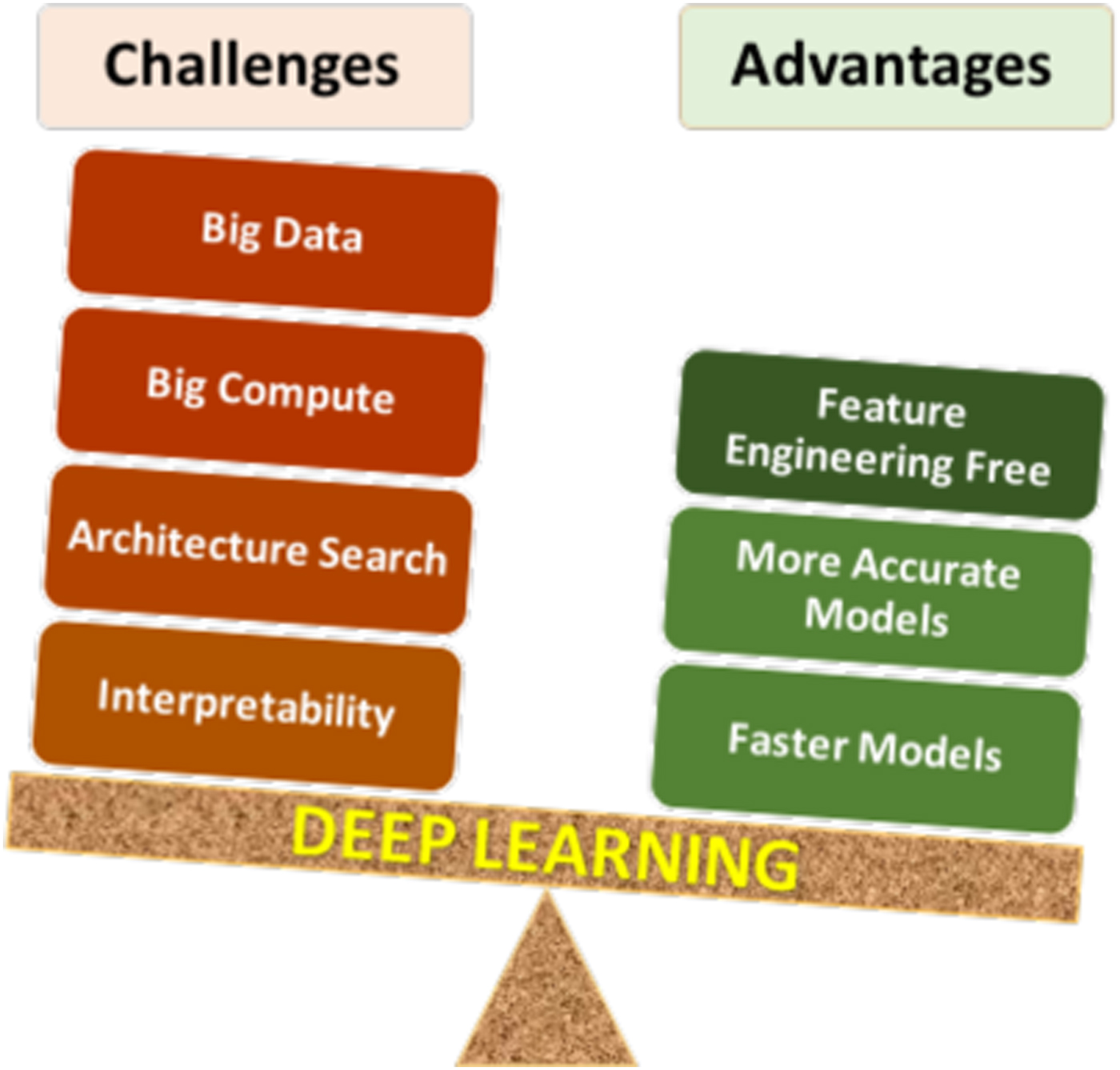
Neural networks are a cornerstone of modern artificial intelligence (AI), enabling machines to perform tasks that traditionally required human intelligence. These models consist of layers of interconnected nodes (neurons) that process input data, learn from it, and produce outputs through weighted connections. The architecture mimics the brain’s neural structure, though simplified for computational efficiency. Neural networks are particularly effective in handling unstructured data, such as images, audio, and text, where traditional algorithms struggle. Their ability to generalize from examples makes them invaluable in fields like healthcare (diagnostic imaging), finance (fraud detection), and autonomous systems (self-driving cars). However, their complexity and resource demands pose challenges in deployment and scalability.
#History / Background
#Early Foundations (1940s–1960s)
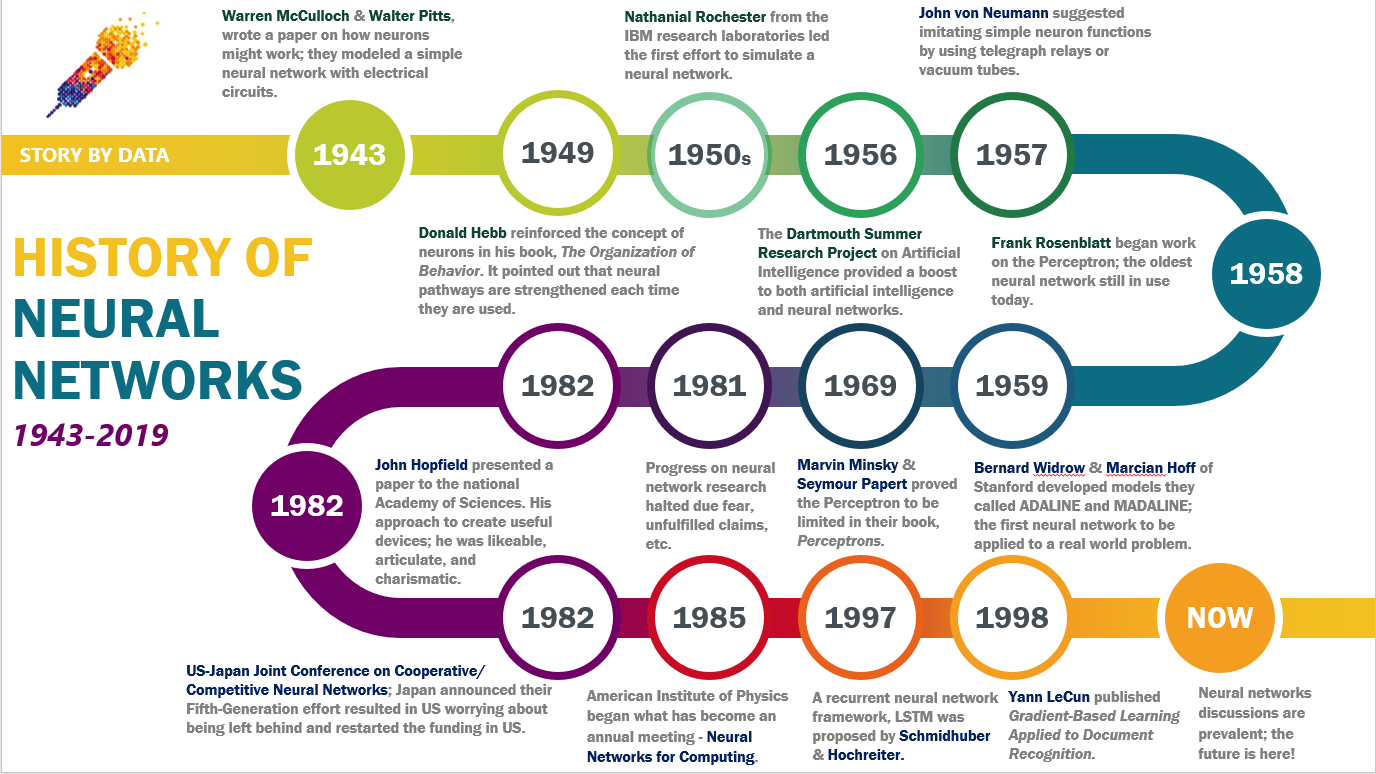
The concept of neural networks traces back to the 1940s with the work of Warren McCulloch and Walter Pitts, who proposed a mathematical model of artificial neurons. In 1958, Frank Rosenblatt developed the Perceptron, the first functional neural network, capable of basic pattern recognition. However, limitations in computational power and theoretical understanding led to a decline in research during the 1970s, known as the "AI Winter."
#Revival and Breakthroughs (1980s–2000s)
The resurgence of neural networks began in the 1980s with the introduction of backpropagation, a method for training multi-layer networks. Geoffrey Hinton’s work on deep learning in the 2000s revolutionized the field, enabling networks with multiple hidden layers to solve complex problems. The ImageNet competition (2012) marked a turning point, where a convolutional neural network (CNN) achieved unprecedented accuracy in image classification, sparking widespread adoption.
#Modern Era
(2010s–Present)
Advancements in hardware (GPUs, TPUs) and big data have accelerated neural network development. Architectures like Transformers (2017) and Generative Adversarial Networks (GANs) have expanded capabilities in natural language processing and generative AI. Today, neural networks underpin technologies such as chatbots, recommendation systems, and advanced robotics.
#How It Works
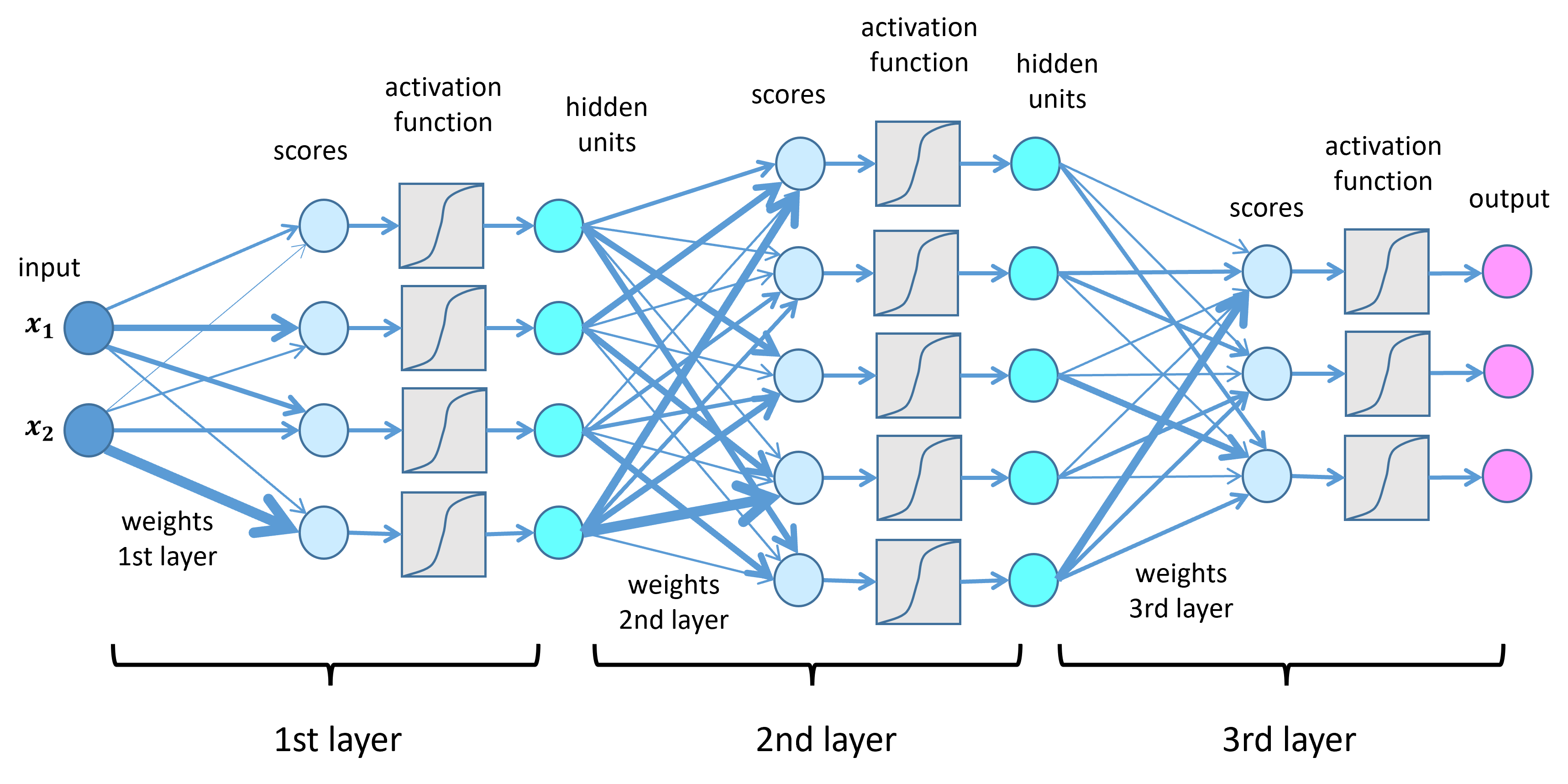
#Basic Structure A neural network comprises three primary layers:
- Input Layer: Receives raw data (e.g., pixels in an image, words in a sentence).
- Hidden Layers: Intermediate layers where computations occur. Each neuron applies a weighted sum to inputs, followed by an activation function (e.g., ReLU, sigmoid) to introduce non-linearity.
- Output Layer: Produces the final prediction or classification.
#Training Process
Neural networks learn through supervised learning, where labeled data is fed into the network. The loss function (e.g., mean squared error, cross-entropy) measures the difference between predicted and actual outputs. Backpropagation adjusts weights via optimization algorithms like gradient descent to minimize error. This iterative process continues until the model achieves satisfactory performance.
#Key Concepts
- Weights and Biases: Parameters adjusted during training to improve accuracy.
- Activation Functions: Introduce non-linearity (e.g., ReLU, tanh) to enable complex mappings.
- Overfitting: Occurs when a model memorizes training data but fails to generalize. Techniques like dropout and regularization mitigate this.
- Hyperparameters: Configurable settings (e.g., learning rate, batch size) that influence training.
#Important Facts
- Universal Approximation Theorem: A neural network with a single hidden layer can approximate any continuous function, given sufficient neurons.
- Deep Learning: Networks with multiple hidden layers (deep networks) outperform shallow ones in tasks like speech and image recognition.
- Transfer Learning: Pre-trained models (e.g., BERT, ResNet) can be fine-tuned for specific tasks, reducing training time and data requirements.
- Hardware Dependency: Training large models (e.g., LLMs) requires specialized hardware like GPUs or TPUs due to high computational demands.
- Ethical Concerns: Bias in training data can lead to discriminatory outcomes, highlighting the need for ethical AI practices.
#Timeline
- Foundational ideas
Core concepts and early methods shape Neural Networks: Pros and Cons.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Neural Networks: Pros and Cons cover?
Covers neural networks: pros and cons, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
Why is Neural Networks: Pros and Cons important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Neural, Networks, Pros before using the ideas in real projects.
#References
- Neural Networks: Pros and Cons terminology and background research
- Neural Networks: Pros and Cons use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Neural case studies, benchmarks, and current industry analysis
Comments
No comments yet. Start the discussion with a useful note.