#Short Answer
Covers deep learning: pros and cons, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
#Infobox
#Overview
Deep learning is a transformative branch of artificial intelligence (AI) that mimics the human brain’s structure and function through deep neural networks. Unlike traditional machine learning, which relies on handcrafted features, deep learning automatically learns hierarchical representations from raw data, enabling breakthroughs in fields such as computer vision, natural language processing (NLP), and reinforcement learning. The core strength of deep learning lies in its ability to process vast amounts of data, identify intricate patterns, and generalize from examples. This has led to its adoption in industries like healthcare (medical imaging, drug discovery), finance (fraud detection, algorithmic trading), and technology (voice assistants, recommendation systems). However, its reliance on large datasets, computational resources, and lack of interpretability pose significant challenges.
#History / Background
#Early Foundations (1940s–1980s)
The conceptual roots of deep learning trace back to the 1940s with the introduction of artificial neurons by Warren McCulloch and Walter Pitts. In the 1950s, Frank Rosenblatt developed the Perceptron, a single-layer neural network, which laid the groundwork for modern AI. However, limitations in computational power and theoretical understanding restricted progress. The 1980s saw the emergence of backpropagation, a key algorithm for training multi-layer neural networks, proposed by Geoffrey Hinton, David Rumelhart, and Ronald Williams. Despite this, deep learning remained underutilized due to the vanishing gradient problem, where gradients in early layers became too small to update weights effectively.
#Revival and Breakthroughs (2000s–2010s)
The 2000s marked a resurgence in deep learning, driven by:
- Increased computational power (GPUs, distributed computing).
- Big data availability (large labeled datasets like ImageNet).
- Architectural innovations such as Convolutional Neural Networks (CNNs) by Yann LeCun (1998) and Long Short-Term Memory (LSTM) networks by Hochreiter and Schmidhuber (1997). The 2012 ImageNet competition was a turning point, where Alex Krizhevsky’s AlexNet (a CNN) achieved unprecedented accuracy, outperforming traditional methods. This event catalyzed widespread adoption of deep learning across industries.
#Modern Era
(2020s–Present)
Today, deep learning powers large language models (LLMs) like GPT-3/4, DALL·E for image generation, and AlphaFold for protein folding prediction. Advances in transformers (Vaswani et al., 2017) have revolutionized NLP, enabling models like BERT and T5 to understand context and semantics at scale.
#How It Works
#Neural Network Architecture
Deep learning models are composed of layers of interconnected nodes (neurons), organized into:
- Input Layer: Receives raw data (e.g., pixels in an image, words in a sentence).
- Hidden Layers: Intermediate layers that extract features hierarchically.
- Convolutional Layers (CNNs): Detect spatial patterns (edges, textures).
- Recurrent Layers (RNNs/LSTMs): Process sequential data (time series, text).
- Fully Connected Layers: Combine features for final prediction.
- Output Layer: Produces the final result (e.g., class probabilities, regression values).
#Key Techniques
- Backpropagation: Adjusts weights by propagating error gradients backward through the network.
- Activation Functions: Introduce non-linearity (e.g., ReLU, Sigmoid, Tanh) to enable complex learning.
- Optimization Algorithms: Stochastic Gradient Descent (SGD), Adam, RMSprop minimize loss functions.
- Regularization: Techniques like dropout and batch normalization prevent overfitting.
#Training Process
- Data Preparation: Raw data is preprocessed (normalization, augmentation) and split into training/validation/test sets.
- Model Initialization: Weights are randomly initialized or pretrained.
- Forward Pass: Input data propagates through the network to generate predictions.
- Loss Calculation: A loss function (e.g., cross-entropy, MSE) measures prediction error.
- Backward Pass: Gradients are computed via backpropagation and weights are updated.
- Iteration: The process repeats until the model converges (loss stabilizes).
#Important Facts
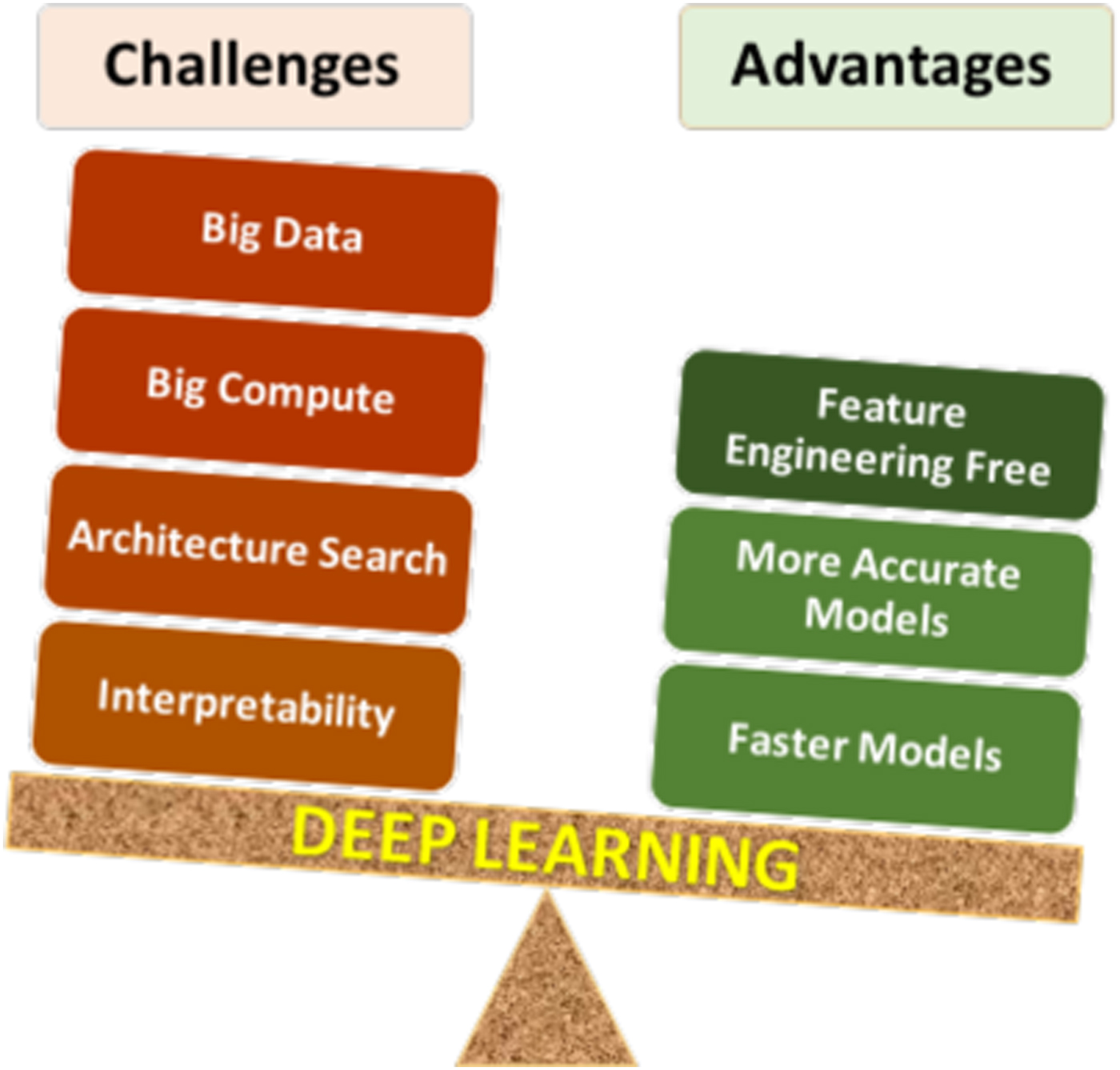
#Advantages
- High Accuracy: Deep learning outperforms traditional methods in tasks like image classification (e.g., 99%+ accuracy on MNIST) and NLP (e.g., BERT’s F1 score of 94% on SQuAD).
- Automation: Reduces the need for manual feature engineering by learning representations directly from data.
- Scalability: Can leverage distributed computing (e.g., TensorFlow on TPUs/GPUs) for large-scale training.
- Versatility: Applicable to diverse domains, from medical diagnosis to autonomous driving.
- Transfer Learning: Pretrained models (e.g., ResNet, BERT) can be fine-tuned for new tasks with minimal data.
#Disadvantages
- Computational Cost: Training large models (e.g., GPT-3 with 175 billion parameters) requires expensive hardware (e.g., NVIDIA A100 GPUs, TPUs).
- Data Hunger: Performance degrades with insufficient labeled data; synthetic data (e.g., GANs) can mitigate this but introduces biases.
- Black-Box Nature: Lack of interpretability makes debugging and trust difficult (e.g., medical or legal applications).
- Overfitting: Models may memorize training data without generalizing (mitigated by regularization, dropout).
- Ethical Concerns: Bias in training data can lead to discriminatory outcomes (e.g., facial recognition inaccuracies for minorities).
#Key Metrics
| Metric | Description | |---------------------|---------------------------------------------------------------------------------| | Accuracy | Percentage of correct predictions. | | Precision | True positives / (True positives + False positives). | | Recall | True positives / (True positives + False negatives). | | F1 Score | Harmonic mean of precision and recall. | | Loss | Measures error between predictions and true values (e.g., cross-entropy). | | AUC-ROC | Area under the Receiver Operating Characteristic curve (for classification). |
#Timeline
- Foundational ideas
Core concepts and early methods shape Deep Learning: Pros and Cons.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Deep Learning: Pros and Cons cover?
Covers deep learning: pros and cons, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
Why is Deep Learning: Pros and Cons important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Deep, Learning, Pros before using the ideas in real projects.
#References
- Deep Learning: Pros and Cons terminology and background research
- Deep Learning: Pros and Cons use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Deep case studies, benchmarks, and current industry analysis



Comments
No comments yet. Start the discussion with a useful note.