
#Short Answer
Covers machine learning: pros and cons, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
#Infobox
#Overview
Machine learning is a transformative technology that allows computers to identify patterns, make decisions, and predict outcomes based on data inputs. Unlike traditional programming, where rules are explicitly defined, ML systems derive their own rules by analyzing large datasets. This capability has revolutionized industries by enabling automation, enhancing decision-making, and uncovering insights that were previously inaccessible. The field is broadly categorized into three main types:
- Supervised Learning: Models are trained on labeled data (input-output pairs) to make predictions or classifications.
- Unsupervised Learning: Models identify patterns or groupings in unlabeled data (e.g., clustering, dimensionality reduction).
- Reinforcement Learning: Models learn by interacting with an environment, receiving rewards or penalties for actions (e.g., robotics, game AI). Machine learning’s versatility has led to its integration across sectors, including healthcare (disease diagnosis), finance (fraud detection), and technology (recommendation systems).
#History / Background
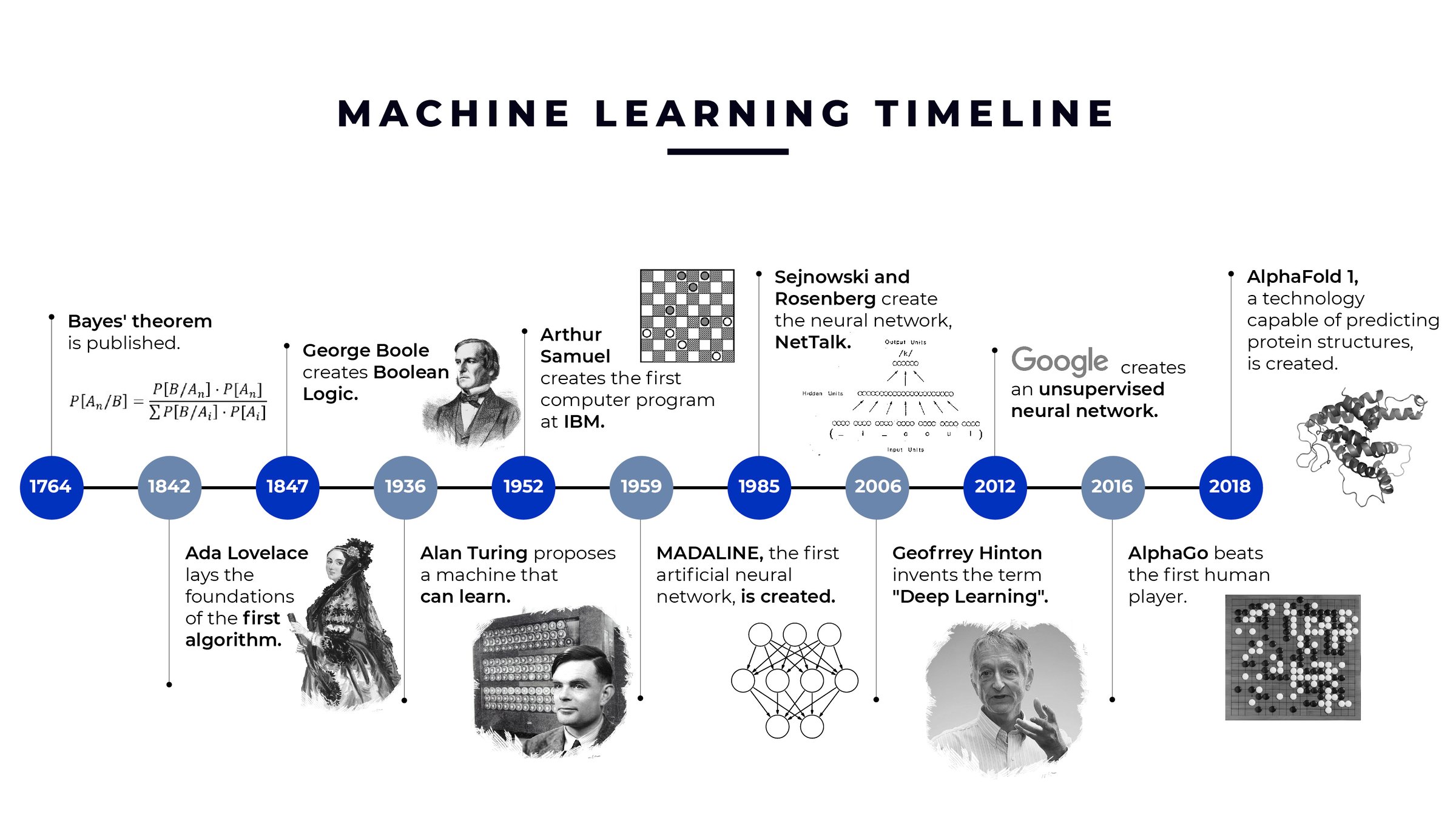
The origins of machine learning trace back to the mid-20th century, with foundational contributions from mathematicians, statisticians, and computer scientists.
- 1943: Warren McCulloch and Walter Pitts proposed the first mathematical model of a neural network, simulating the human brain’s structure.
- 1950: Alan Turing introduced the "Turing Test," a criterion for determining a machine’s ability to exhibit intelligent behavior.
- 1952: Arthur Samuel developed the first self-learning program, a checkers-playing AI that improved with experience.
- 1956: The term "artificial intelligence" was coined at the Dartmouth Conference, marking the formal birth of AI as a field.
- 1967: The "Nearest Neighbor" algorithm was introduced, enabling pattern recognition in data.
- 1980s–1990s: Machine learning evolved with the advent of statistical learning theory and algorithms like decision trees and support vector machines (SVMs).
- 2000s–Present: The rise of big data, cloud computing, and deep learning (e.g., convolutional neural networks, transformers) propelled ML into mainstream applications, powering technologies like voice assistants, autonomous vehicles, and personalized recommendations. Key milestones include:
- 2012: AlexNet, a deep neural network, achieved breakthrough performance in image recognition.
- 2016: AlphaGo defeated a world champion Go player, demonstrating the power of reinforcement learning.
- 2020s: Large language models (LLMs) like GPT-3 and DALL·E showcased the potential of generative AI.
#How It Works
Machine learning operates through a cyclical process involving data, algorithms, training, and evaluation. The core steps are:
#1. Data Collection and Preparation
- Data Gathering: Collecting relevant datasets (structured or unstructured) from sources like databases, sensors, or user interactions.
- Preprocessing: Cleaning data (handling missing values, outliers), normalizing features, and transforming data into a suitable format (e.g., images to pixel arrays, text to numerical vectors).
#2. Model Selection - Choosing an algorithm based on the problem type:
- Classification: Predicting discrete labels (e.g., spam detection).
- Regression: Predicting continuous values (e.g., house price estimation).
- Clustering: Grouping similar data points (e.g., customer segmentation).
- Dimensionality Reduction: Simplifying data (e.g., PCA for visualization).
#3. Training - The model learns from the training data by adjusting its internal parameters (e.g., weights in a neural network) to minimize error. Techniques include:
- Gradient Descent: Iteratively updating parameters to reduce loss.
- Backpropagation: Used in neural networks to propagate errors backward and adjust weights.
#4. Evaluation - Assessing model performance using metrics like:
- Accuracy: Percentage of correct predictions.
- Precision/Recall: For classification tasks.
- Mean Squared Error (MSE): For regression tasks. - Techniques like cross-validation ensure the model generalizes well to unseen data.
#5. Deployment and Monitoring - Deploying the model in production environments (e.g., cloud platforms, edge devices). - Continuous monitoring for performance drift, bias, or concept drift (where data distributions change over time).
#Important Facts
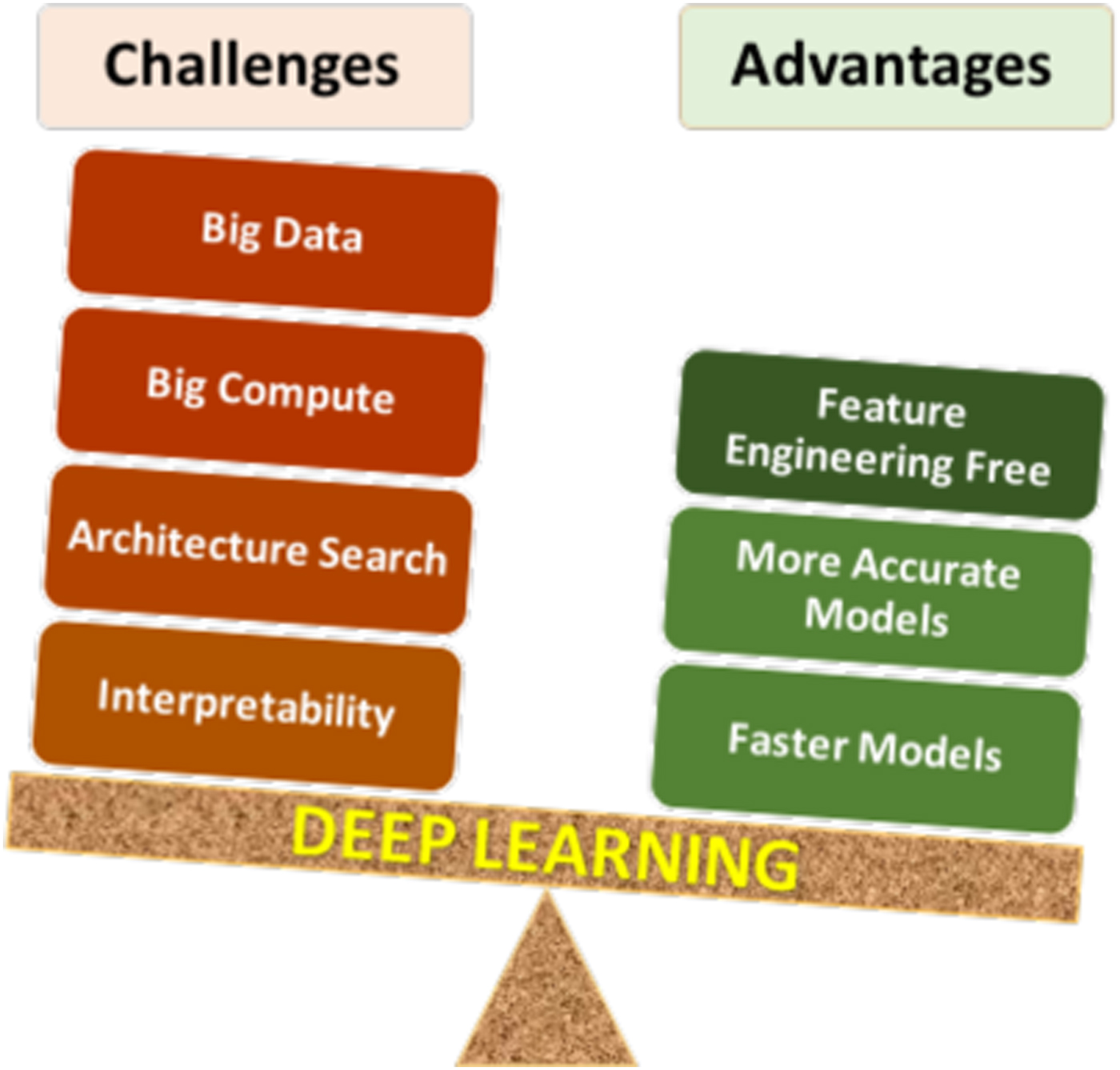
- Data Dependency: ML models require large, high-quality datasets. Poor or biased data leads to inaccurate or unfair outcomes.
- Computational Power: Training complex models (e.g., deep neural networks) demands significant computational resources, often requiring GPUs or TPUs.
- Overfitting vs. Underfitting:
- Overfitting: Model memorizes training data but fails to generalize (high variance).
- Underfitting: Model is too simple to capture patterns (high bias).
- Interpretability: Many ML models (e.g., deep learning) are "black boxes," making it difficult to explain their decisions. Techniques like SHAP (SHapley Additive exPlanations) aim to address this.
- Ethical Concerns: Bias in training data can lead to discriminatory outcomes (e.g., facial recognition inaccuracies for certain demographics). Privacy issues arise from data collection and usage.
- Automation Bias: Over-reliance on ML systems can lead to reduced human oversight and critical errors.
#Timeline
- Foundational ideas
Core concepts and early methods shape Machine Learning: Pros and Cons.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Machine Learning: Pros and Cons cover?
Covers machine learning: pros and cons, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
Why is Machine Learning: Pros and Cons important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Machine, Learning, Pros before using the ideas in real projects.
#References
- Machine Learning: Pros and Cons terminology and background research
- Machine Learning: Pros and Cons use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Machine case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.