#Short Answer
Explains how to train your first ai model, including the main process, tools, examples, risks, and practical implementation steps.
#Infobox
#Overview
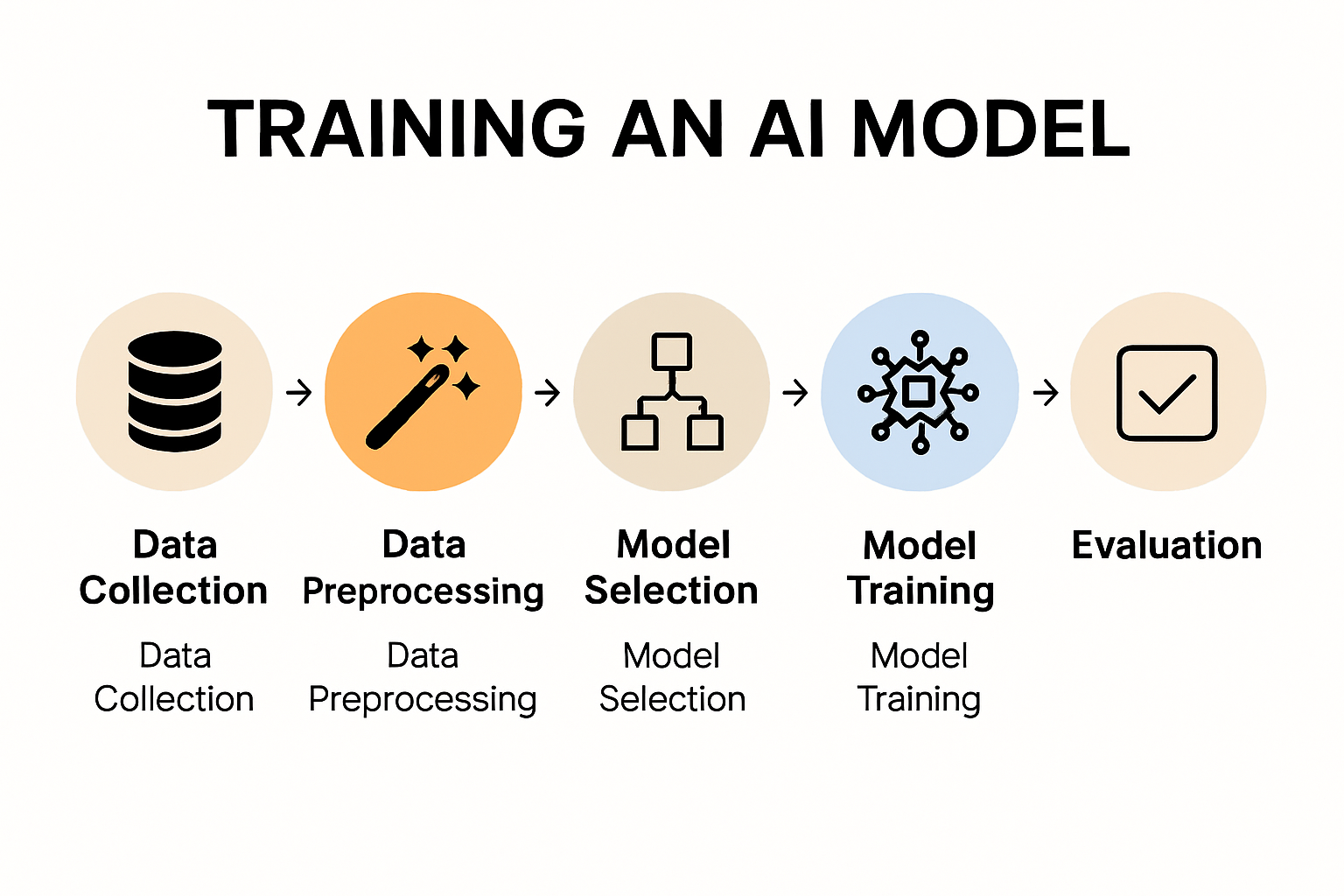
Training an AI model is the process of teaching a machine learning algorithm to recognize patterns, make decisions, or generate outputs based on input data. Unlike traditional programming, where explicit instructions are provided, AI models learn from examples, improving their performance through exposure to data. This approach is foundational to modern applications in natural language processing, computer vision, recommendation systems, and autonomous systems. The process typically begins with problem definition, followed by data collection and preprocessing, model selection, training, evaluation, and deployment. Advances in deep learning and computational power have democratized AI development, enabling individuals and organizations to build custom models without extensive expertise in mathematics or computer science.
#History / Background
The concept of training machines to learn from data traces back to the mid-20th century. In 1950, Alan Turing proposed the "Turing Test" as a measure of machine intelligence, laying early groundwork for AI. The 1956 Dartmouth Conference is often cited as the birth of AI as a formal discipline. Early AI models relied on symbolic logic and rule-based systems, which proved limited in handling complex, real-world data. The 1980s saw the rise of machine learning, with algorithms like decision trees and support vector machines gaining prominence. However, these methods required significant feature engineering and struggled with high-dimensional data. The breakthrough came in the 2010s with the advent of deep learning, powered by neural networks with multiple layers. The ImageNet competition in 2012, where a convolutional neural network (CNN) dramatically outperformed traditional methods, marked a turning point. Frameworks like TensorFlow (2015) and PyTorch (2016) further simplified model development, enabling widespread adoption. Today, AI training is integral to industries such as healthcare (diagnostic imaging), finance (fraud detection), and retail (personalized recommendations). Open-source tools and cloud computing have lowered barriers to entry, allowing even beginners to experiment with training models.
#How It Works
#
- Problem Definition The first step is to clearly define the problem the AI model will solve. Common tasks include:
- Classification: Assigning input data to predefined categories (e.g., spam detection).
- Regression: Predicting continuous values (e.g., house price estimation).
- Clustering: Grouping similar data points (e.g., customer segmentation).
- Generative AI: Creating new content (e.g., text, images).
#
- Data Collection High-quality data is critical. Sources may include: - Public datasets (e.g., Kaggle, UCI Machine Learning Repository). - Internal databases or APIs. - Web scraping (with legal considerations). - Synthetic data generation.
#
- Data Preprocessing Raw data is rarely suitable for training. Preprocessing steps include:
- Cleaning: Handling missing values, removing duplicates, and correcting errors.
- Normalization: Scaling features to a standard range (e.g., 0 to 1).
- Encoding: Converting categorical data (e.g., text labels) into numerical form.
- Feature Engineering: Creating new features or selecting relevant ones.
- Augmentation: For image or text data, techniques like rotation or synonym replacement can increase dataset size.
#
- Model Selection Choosing the right algorithm depends on the problem:
- Linear Regression: For simple regression tasks.
- Decision Trees / Random Forests: For classification and regression with interpretability.
- Support Vector Machines (SVM): Effective for high-dimensional data.
- Neural Networks: Ideal for complex patterns (e.g., CNNs for images, RNNs for sequences).
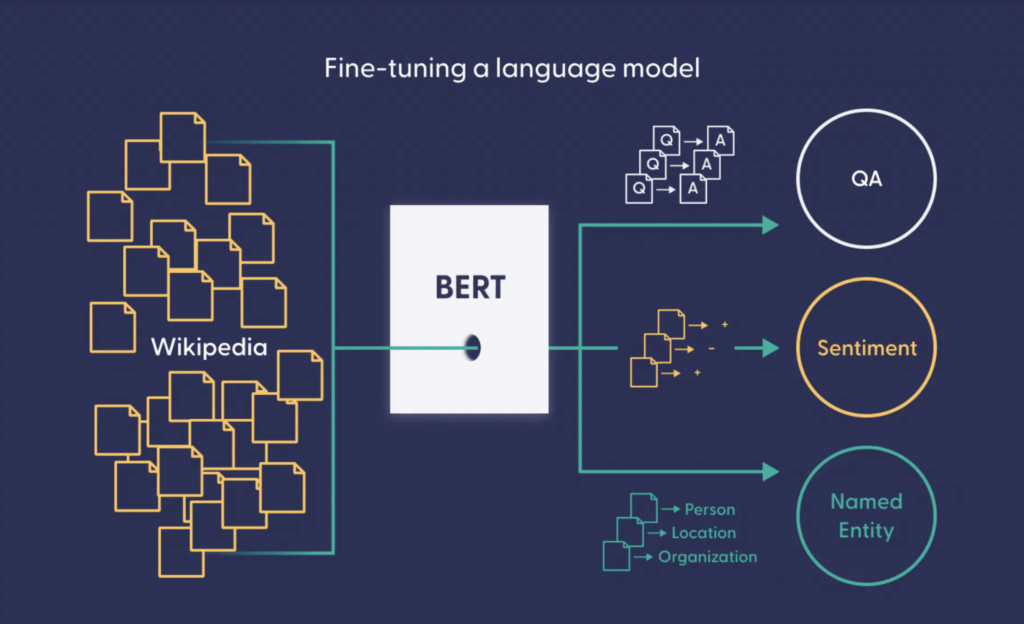
- Transformers: State-of-the-art for natural language processing (e.g., BERT, GPT).
#
- Training the Model The model learns by adjusting its parameters to minimize a loss function. Key concepts:
- Loss Function: Measures the difference between predictions and actual values (e.g., Mean Squared Error for regression, Cross-Entropy for classification).
- Optimization: Algorithms like Stochastic Gradient Descent (SGD) or Adam update parameters iteratively.
- Hyperparameters: Configurable settings (e.g., learning rate, batch size, epochs) that influence training.
- Validation: A separate dataset is used to tune hyperparameters and prevent overfitting.
#
- Evaluation Performance metrics depend on the task:
- Classification: Accuracy, Precision, Recall, F1-Score, ROC-AUC.
- Regression: Mean Absolute Error (MAE), Root Mean Squared Error (RMSE).
- Clustering: Silhouette Score, Davies-Bouldin Index.
- Generative Models: Perplexity (for language models), Inception Score (for images).
#
- Deployment Once trained, the model can be deployed in various environments:
- Cloud Platforms: AWS SageMaker, Google Vertex AI, Azure Machine Learning.
- Edge Devices: Mobile apps or IoT devices using frameworks like TensorFlow Lite.
- APIs: Exposing the model via RESTful endpoints for integration with other systems.
#
- Monitoring and Maintenance AI models degrade over time due to changing data distributions ("concept drift"). Continuous monitoring involves: - Tracking performance metrics. - Retraining with new data. - Updating the model to adapt to new patterns.
#Important Facts
- Bias-Variance Tradeoff: A model with high bias underfits the data (too simple), while high variance leads to overfitting (memorizing noise).
- Curse of Dimensionality: As the number of features increases, the data becomes sparse, making learning harder.
- Transfer Learning: Pre-trained models (e.g., ResNet for images, BERT for text) can be fine-tuned for specific tasks, reducing training time and data requirements.
- Explainability: Techniques like SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations) help interpret model decisions.
- Ethical Considerations: Bias in training data can lead to discriminatory outcomes. Fairness-aware algorithms and diverse datasets are essential.
- Hardware Requirements: Training large models (e.g., LLMs) often requires GPUs or TPUs for efficiency.
#Timeline
- Foundational ideas
Core concepts and early methods shape How to Train Your First AI Model.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does How to Train Your First AI Model cover?
Explains how to train your first ai model, including the main process, tools, examples, risks, and practical implementation steps.
Why is How to Train Your First AI Model important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Train, First, AI before using the ideas in real projects.
#References
- How to Train Your First AI Model terminology and background research
- How to Train Your First AI Model use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Train case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.