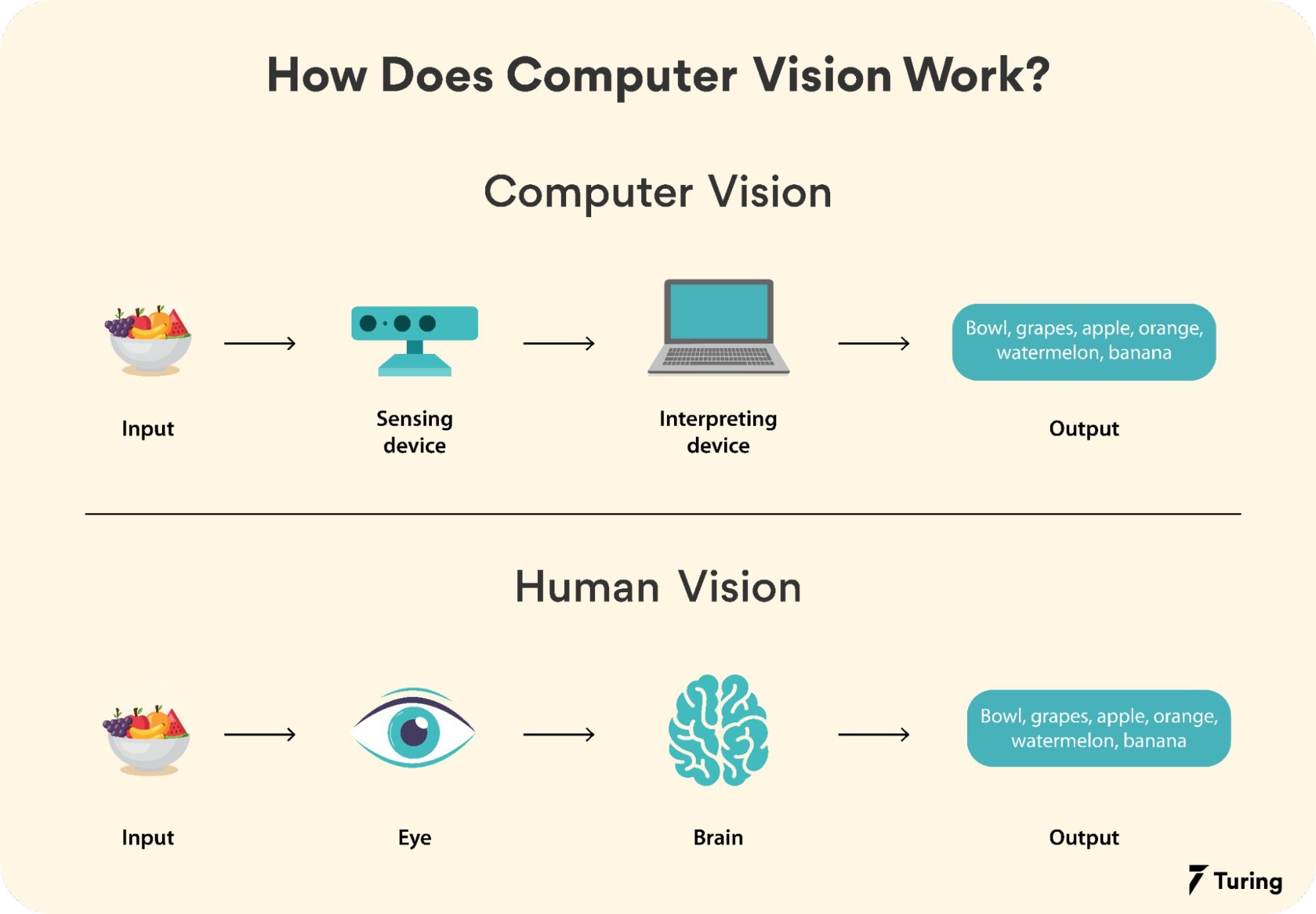
#Short Answer
Explains how does computer vision work?, including the main process, tools, examples, risks, and practical implementation steps.
#Infobox
#Overview
Computer vision is a multidisciplinary field that bridges computer science, mathematics, and cognitive science to enable machines to derive meaningful information from visual inputs. Unlike traditional image processing, which focuses on manipulating pixel data, computer vision aims to replicate the human ability to interpret and act upon visual data. This capability is fundamental to modern AI systems, powering applications from self-driving cars to advanced medical diagnostics. At its core, computer vision involves several key processes:
- Image Acquisition: Capturing visual data using cameras or sensors.
- Preprocessing: Enhancing image quality through techniques like noise reduction, normalization, and contrast adjustment.
- Feature Extraction: Identifying patterns, edges, textures, and other salient features within an image.
- Object Recognition: Classifying and detecting objects, faces, or scenes using machine learning models.
- Decision Making: Interpreting the extracted information to make informed decisions or predictions. The field has evolved significantly with advancements in deep learning, particularly convolutional neural networks (CNNs), which have revolutionized tasks like image classification and object detection.
#History / Background
#Early Foundations (1950s–1970s)
The origins of computer vision can be traced back to the 1950s, when researchers began exploring ways to automate visual tasks. Early work focused on simple pattern recognition and optical character recognition (OCR). In 1959, David Hubel and Torsten Wiesel conducted groundbreaking research on the visual cortex of cats, which later influenced computational models of vision. The term "computer vision" gained prominence in the 1960s, with projects like MIT’s "Summer Vision Project" (1966), which aimed to develop a system that could describe a scene from an image. However, the limitations of early computers and algorithms hindered progress.
#Rise of Machine Learning
(1980s–2000s)
The 1980s saw the introduction of edge detection algorithms, such as the Canny edge detector, which improved the ability to identify boundaries in images. The development of support vector machines (SVMs) in the 1990s further advanced object recognition tasks. A major milestone was the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), launched in 2010, which spurred innovation in deep learning. The breakthrough came in 2012 when AlexNet, a deep CNN developed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton, achieved unprecedented accuracy in image classification, winning the ILSVRC by a significant margin.
#Modern Era
(2010s–Present)
The 2010s marked the deep learning revolution, with CNNs becoming the dominant approach for computer vision tasks. Key advancements include:
- Region-based CNNs (R-CNNs) for object detection.
- Generative Adversarial Networks (GANs) for image synthesis.
- Transformer-based models, such as Vision Transformers (ViTs), which leverage self-attention mechanisms for improved performance. Today, computer vision is integral to industries like healthcare (e.g., tumor detection in MRI scans), automotive (e.g., Tesla’s Autopilot), and retail (e.g., Amazon’s cashier-less stores).
#How It Works
#Image Acquisition The first step in computer vision is capturing visual data. This is typically done using:
- Digital cameras (RGB, depth, infrared, or thermal sensors).
- LiDAR (for 3D mapping in autonomous vehicles).
- Drones and satellites (for aerial surveillance and remote sensing).
#Preprocessing Raw images often contain noise, distortions, or irrelevant information. Preprocessing techniques enhance image quality and prepare data for analysis:
- Noise Reduction: Filters like Gaussian blur or median filtering remove random variations.
- Normalization: Adjusting pixel intensity values to a standard range (e.g., 0–255 to 0–1).
- Contrast Enhancement: Techniques like histogram equalization improve visibility of features.
- Geometric Transformations: Scaling, rotation, or cropping standardize images for consistent analysis.
#Feature Extraction Feature extraction identifies meaningful patterns in images. Traditional methods include:
- Edge Detection: Algorithms like Sobel or Canny detect boundaries between objects.
- Corner Detection: Harris corner detector identifies points of interest.
- Texture Analysis: Methods like Local Binary Patterns (LBP) extract texture features. Modern approaches rely on deep learning models, particularly CNNs, which automatically learn hierarchical features:
- Low-level features (edges, colors) are extracted in early layers.
- Mid-level features (shapes, textures) are captured in intermediate layers.
- High-level features (object parts, entire objects) are identified in deeper layers.
#Object Recognition and Detection Object recognition involves classifying an image into predefined categories (e.g., "cat" or "dog"), while object detection localizes multiple objects within an image (e.g., "person," "car," "traffic light"). Key techniques include:
- CNNs: Models like ResNet or EfficientNet classify images with high accuracy.
- Region Proposal Networks (RPNs): Used in Faster R-CNN to generate bounding boxes for objects.
- YOLO (You Only Look Once): A real-time object detection system that processes images in a single pass.
- Segmentation Models: Mask R-CNN or U-Net perform pixel-level segmentation to identify object boundaries.
#Decision Making and Action The final step involves interpreting the extracted information to make decisions. For example:
- Autonomous Vehicles: A self-driving car uses computer vision to detect pedestrians, traffic signs, and lane markings, then adjusts its path accordingly.
- Medical Imaging: AI models analyze X-rays or MRIs to identify abnormalities like tumors or fractures.
- Facial Recognition: Systems match facial features to a database for authentication or surveillance.
#Challenges and Limitations Despite advancements, computer vision faces several challenges:
- Variability in Lighting and Occlusion: Changes in lighting or partial object visibility can reduce accuracy.
- Real-Time Processing: High computational demands limit deployment in resource-constrained environments.
- Bias in Datasets: Models trained on biased data may perform poorly on underrepresented groups.
- Interpretability: Deep learning models often operate as "black boxes," making it difficult to understand their decisions.
#Important Facts
- Human vs. Machine Vision: - The human eye has ~120 million rod cells for low-light vision and ~6–7 million cone cells for color perception. - Computer vision systems can process images in milliseconds but lack the contextual understanding of human vision.
- Deep Learning Dominance: - CNNs, introduced by Yann LeCun in the 1990s, are the backbone of modern computer vision. - The ImageNet dataset contains over 14 million labeled images across 20,000 categories.
- Applications by Industry:
- Healthcare: AI models detect diabetic retinopathy in retinal scans with 90%+ accuracy.
- Retail: Amazon Go stores use computer vision to track shoppers and items without checkout counters.
- Agriculture: Drones equipped with multispectral cameras monitor crop health and predict yields.
- Ethical Concerns:
- Privacy Issues: Facial recognition systems raise concerns about mass surveillance.
- Deepfakes: AI-generated fake images and videos can spread misinformation.
- Bias: Models trained on predominantly Western faces may perform poorly on diverse populations.
- Hardware Advancements:
- GPUs and TPUs: Accelerate training and inference of deep learning models.
- Edge AI: Devices like NVIDIA Jetson enable real-time computer vision on low-power hardware.
#Timeline
- Foundational ideas
Core concepts and early methods shape How Does Computer Vision Work?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does How Does Computer Vision Work? cover?
Explains how does computer vision work?, including the main process, tools, examples, risks, and practical implementation steps.
Why is How Does Computer Vision Work? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Computer Vision decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Does, Computer, Vision before using the ideas in real projects.
#References
- How Does Computer Vision Work? terminology and background research
- How Does Computer Vision Work? use cases, implementation examples, and limitations
- Computer Vision best practices, standards, and risk guidance
- Does case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.