#Short Answer
Explains how do ai algorithms work?, including the main process, tools, examples, risks, and practical implementation steps.
#Infobox
#Overview
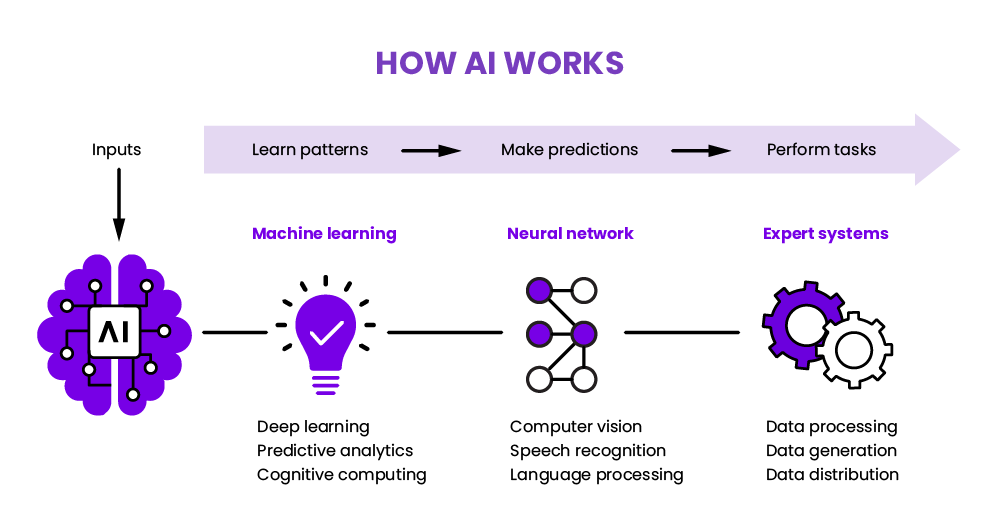
Artificial Intelligence (AI) algorithms are the backbone of modern AI systems, enabling machines to perform tasks that traditionally require human cognition. These algorithms are broadly categorized into rule-based systems, machine learning (ML) models, and deep learning (DL) networks, each with distinct methodologies and applications. Rule-based systems rely on predefined instructions, while ML and DL models learn from data, improving their performance over time through iterative training. The core objective of AI algorithms is to generalize from input data to make accurate predictions or decisions in unseen scenarios. This generalization is achieved through mathematical representations of data, such as probability distributions, graph structures, or neural network weights. The effectiveness of an AI algorithm depends on factors like data quality, model architecture, computational efficiency, and hyperparameter tuning. AI algorithms power a wide range of applications, including:
- Natural Language Processing (NLP): Enabling chatbots, translation services, and sentiment analysis.
- Computer Vision: Facilitating image recognition, object detection, and autonomous driving.
- Predictive Analytics: Used in finance for fraud detection and in healthcare for disease prognosis.
- Robotics: Allowing machines to navigate environments and perform complex tasks.
#History / Background
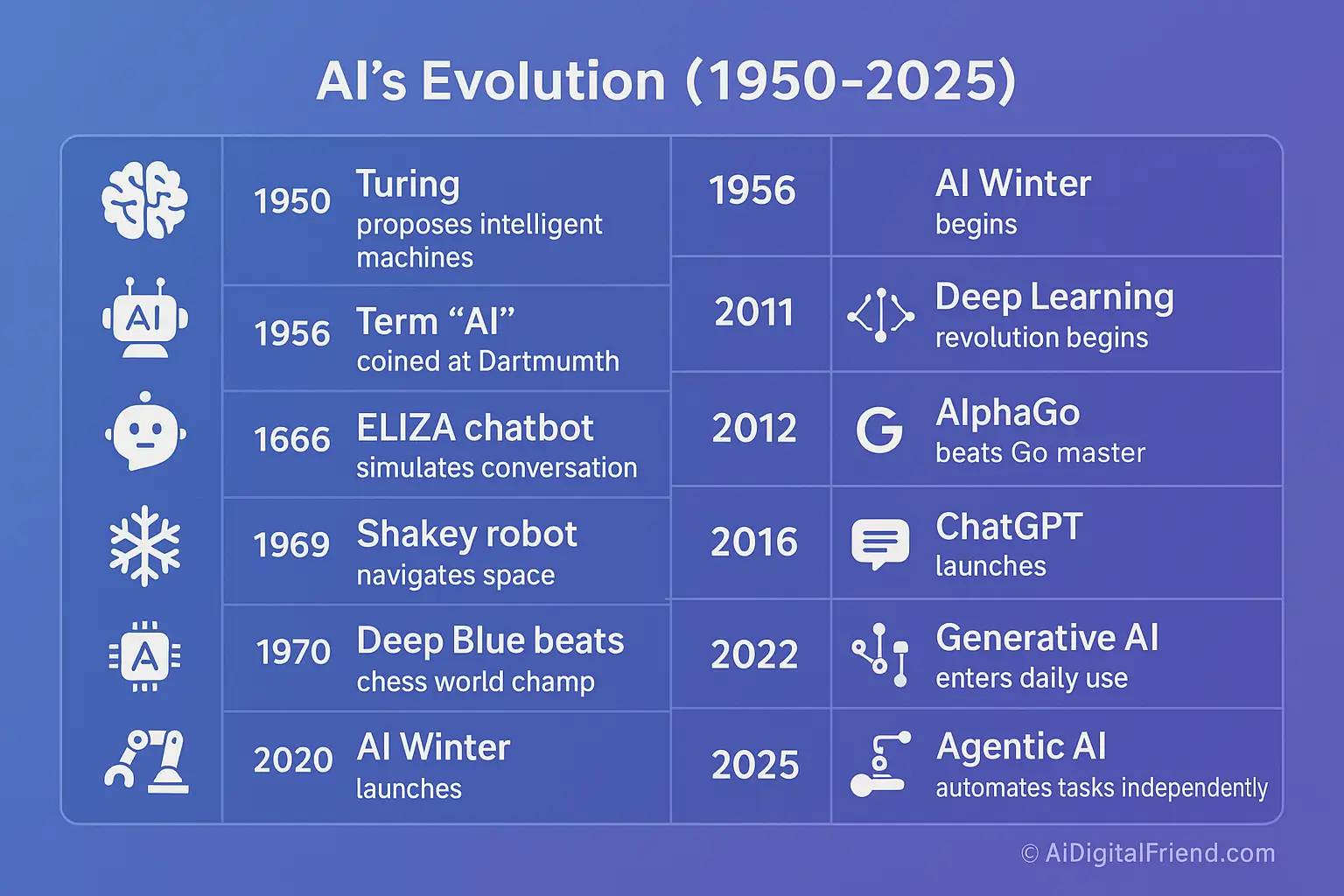
The evolution of AI algorithms spans over seven decades, marked by theoretical breakthroughs, computational advancements, and paradigm shifts in problem-solving approaches.
#Early Foundations (1950s–1970s)
- 1950: Alan Turing proposed the Turing Test, a criterion for machine intelligence, laying the groundwork for AI as a field.
- 1956: The term "Artificial Intelligence" was coined at the Dartmouth Conference, where researchers like John McCarthy and Marvin Minsky explored symbolic reasoning and problem-solving.
- 1958: Frank Rosenblatt developed the Perceptron, an early neural network model for binary classification, though it was limited to linearly separable data.
- 1966: Joseph Weizenbaum created ELIZA, an early NLP program simulating human conversation, demonstrating the potential of symbolic AI.
#The AI Winter and Expert Systems (1970s–1990s)
- 1970s–1980s: The field faced the AI Winter, a period of reduced funding and interest due to overpromised capabilities and computational limitations.
- 1980s: Expert systems gained prominence, using rule-based logic to mimic human expertise in domains like medicine and engineering. Systems like MYCIN (for bacterial infection diagnosis) showcased the power of symbolic reasoning.
- 1986: Backpropagation, a key algorithm for training neural networks, was popularized by David Rumelhart, Geoffrey Hinton, and Ronald Williams, reviving interest in connectionist models.
#The Machine Learning Revolution (1990s–2010s)
- 1997: IBM’s Deep Blue defeated world chess champion Garry Kasparov, highlighting the potential of AI in complex decision-making.
- 1998: Yann LeCun’s LeNet-5, a convolutional neural network (CNN), achieved breakthroughs in handwritten digit recognition, paving the way for modern computer vision.
- 2006: Geoffrey Hinton introduced deep belief networks, demonstrating that deep learning could outperform traditional methods in tasks like speech recognition.
- 2012: A deep neural network won the ImageNet Large Scale Visual Recognition Challenge, marking a turning point for AI’s dominance in computer vision.
#The Deep Learning Era (2010s–Present)
- 2014: Generative Adversarial Networks (GANs) were introduced by Ian Goodfellow, enabling the generation of realistic synthetic data.
- 2017: The Transformer architecture was introduced in the paper "Attention Is All You Need", revolutionizing NLP with models like BERT and GPT.
- 2020s: AI algorithms have become integral to autonomous vehicles, personalized medicine, and climate modeling, with advancements in reinforcement learning and neuro-symbolic AI.
#How It Works
AI algorithms function through a series of interconnected steps, from data ingestion to model deployment. The process can be broadly divided into training and inference phases, with additional stages for preprocessing, evaluation, and optimization.
#1. Data Collection and Preprocessing
- Data Collection: AI algorithms require large, diverse datasets relevant to the task. Sources include structured databases, unstructured text, images, or sensor data.
- Preprocessing: Raw data is cleaned and transformed to improve model performance. Techniques include:
- Normalization: Scaling data to a standard range (e.g., [0, 1]).
- Tokenization: Splitting text into words or subwords for NLP tasks.
- Feature Extraction: Identifying relevant attributes (e.g., edge detection in images).
- Handling Missing Data: Imputing or removing incomplete entries.
#2. Model Selection and Architecture The choice of algorithm depends on the problem type:
- Supervised Learning: Uses labeled data to learn mappings from inputs to outputs. Examples:
- Linear Regression for continuous outputs.
- Decision Trees for classification and regression.
- Support Vector Machines (SVM) for high-dimensional data.
- Unsupervised Learning: Identifies patterns in unlabeled data. Examples:
- Clustering (e.g., K-means) for grouping similar data points.
- Dimensionality Reduction (e.g., PCA) for simplifying data.
- Reinforcement Learning (RL): Trains agents to make sequences of decisions via rewards and penalties (e.g., Q-learning, Deep Q-Networks).
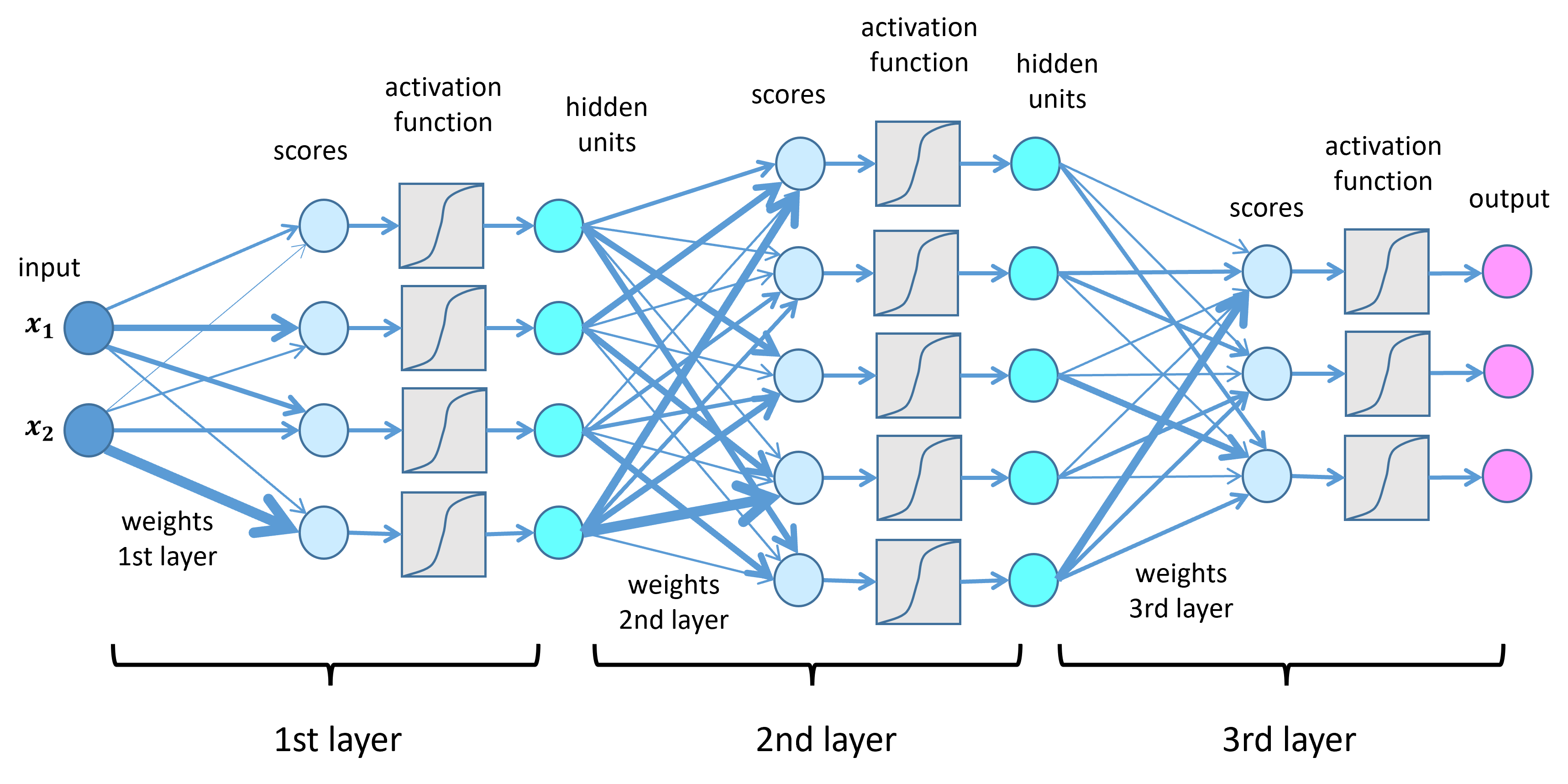
- Deep Learning: Uses multi-layered neural networks to model complex patterns. Architectures include:
- Convolutional Neural Networks (CNNs) for image data.
- Recurrent Neural Networks (RNNs) for sequential data (e.g., time series).
- Transformers for parallel processing of sequences (e.g., NLP tasks).
#3. Training the Model
- Loss Function: Measures the difference between predicted and actual outputs (e.g., Mean Squared Error for regression, Cross-Entropy Loss for classification).
- Optimization: Adjusts model parameters to minimize loss. Common methods:
- Gradient Descent: Iteratively updates weights in the direction of steepest descent.
- Stochastic Gradient Descent (SGD): Uses random subsets of data for efficiency.
- Adam: An adaptive optimization algorithm combining momentum and adaptive learning rates.
- Regularization: Prevents overfitting by penalizing complexity (e.g., L1/L2 regularization, Dropout in neural networks).
#4. Evaluation and Validation
- Training vs. Test Split: Models are evaluated on unseen data to assess generalization.
- Metrics: Performance is measured using:
- Accuracy, Precision, Recall, F1-Score (classification).
- Mean Absolute Error (MAE), R² Score (regression).
- Confusion Matrix for detailed error analysis.
- Cross-Validation: Techniques like k-fold cross-validation ensure robustness by testing on multiple data subsets.
#5. Inference and Deployment
- Inference: The trained model processes new, unseen data to make predictions or decisions.
- Deployment: Models are integrated into applications via APIs, embedded systems, or cloud platforms.
- Monitoring and Maintenance: Continuous evaluation ensures performance degrades gracefully over time (e.g., concept drift detection).
#Important Facts
- Bias-Variance Tradeoff: A fundamental challenge in AI, where reducing bias (underfitting) may increase variance (overfitting), and vice versa.
- Explainability vs. Performance: Highly accurate models (e.g., deep neural networks) often lack interpretability, leading to the rise of explainable AI (XAI) techniques like SHAP and LIME.
- Computational Cost: Training large models (e.g., GPT-3) requires significant resources, with costs running into millions of dollars.
- Ethical Concerns: AI algorithms can perpetuate biases present in training data, raising issues in fairness, privacy, and accountability.
- Hardware Acceleration: Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs) are essential for training deep learning models efficiently.
- Transfer Learning: Pre-trained models (e.g., BERT, ResNet) can be fine-tuned for specific tasks, reducing the need for extensive training data.
- Quantum AI: Emerging research explores quantum computing’s potential to solve certain AI problems exponentially faster than classical methods.
#Timeline
- Foundational ideas
Core concepts and early methods shape How Do AI Algorithms Work?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does How Do AI Algorithms Work? cover?
Explains how do ai algorithms work?, including the main process, tools, examples, risks, and practical implementation steps.
Why is How Do AI Algorithms Work? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Do, AI, Algorithms before using the ideas in real projects.
#References
- How Do AI Algorithms Work? terminology and background research
- How Do AI Algorithms Work? use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Do case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.