
#Short Answer
Explains how do ai models work?, including the main process, tools, examples, risks, and practical implementation steps.
#Infobox
#Overview
AI models are the foundation of modern artificial intelligence systems, enabling machines to mimic human cognitive functions. These models are trained on structured or unstructured data to learn patterns, relationships, and rules that govern the data. Once trained, they can generalize from the training data to make predictions or decisions on new, unseen data. The versatility of AI models has led to their adoption across industries, including healthcare, finance, marketing, and transportation, where they enhance efficiency, accuracy, and scalability. AI models can be broadly classified into three main categories:
- Machine Learning (ML) Models: These models learn from data without explicit programming. They include supervised learning (e.g., linear regression, decision trees), unsupervised learning (e.g., clustering, dimensionality reduction), and semi-supervised learning.
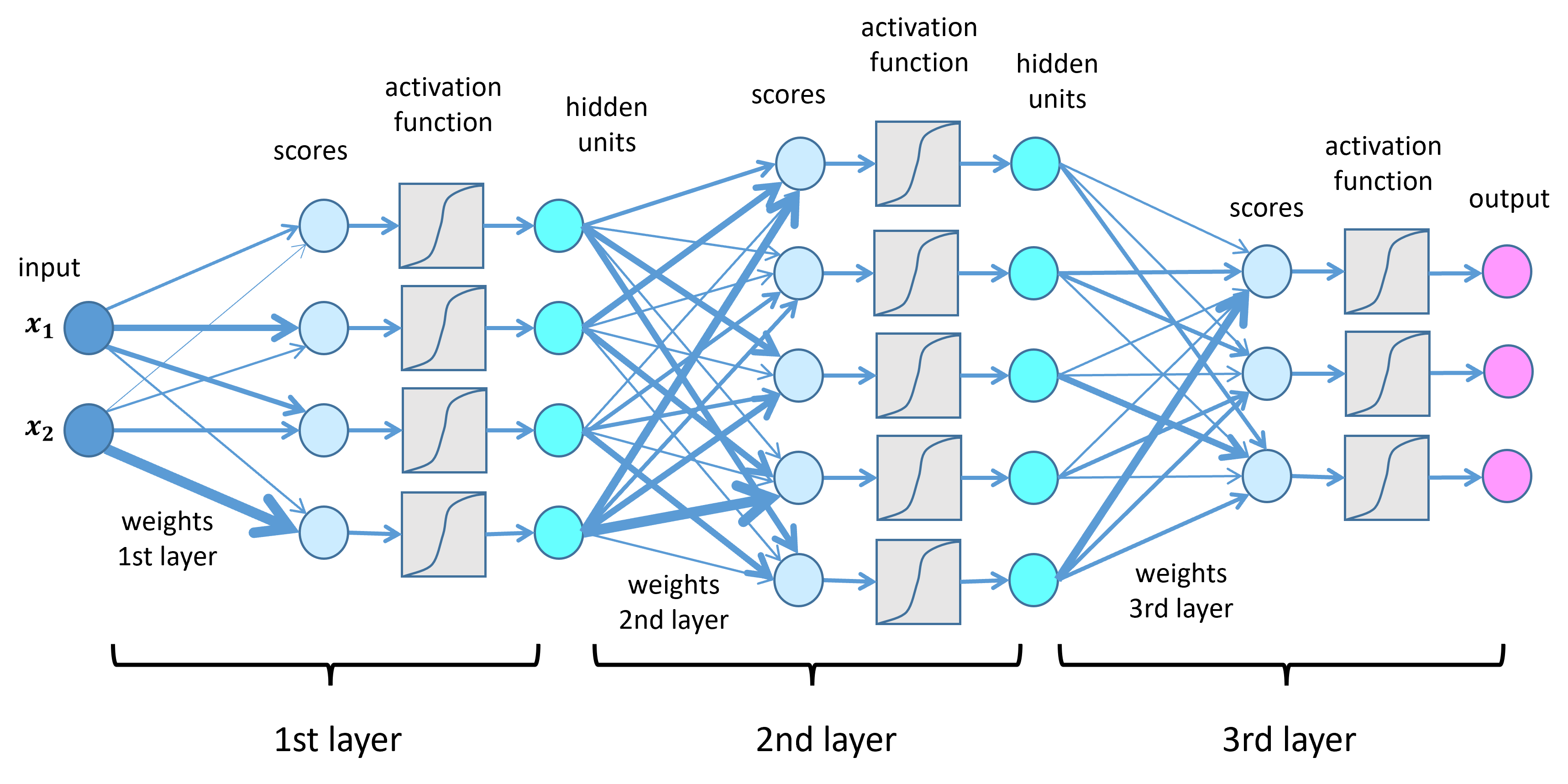
- Deep Learning Models: A subset of machine learning, deep learning models use artificial neural networks with multiple layers (hence "deep") to process complex data such as images, audio, and text. Examples include convolutional neural networks (CNNs) for image recognition and recurrent neural networks (RNNs) for sequence data.
- Generative AI Models: These models generate new content, such as text, images, or music, based on learned patterns from existing data. Examples include large language models (LLMs) like GPT and diffusion models for image generation.
#History / Background
The development of AI models traces back to the mid-20th century, with foundational contributions from pioneers like Alan Turing, who proposed the concept of a "universal machine" capable of performing any computation. The term "artificial intelligence" was coined in 1956 at the Dartmouth Conference, marking the beginning of AI as a formal field of study. Early AI models were rule-based systems that relied on predefined logic to perform tasks. However, these systems were limited in their ability to handle complex or ambiguous data. The advent of machine learning in the 1980s and 1990s introduced models that could learn from data, such as decision trees and support vector machines (SVMs). The breakthrough of deep learning in the 2000s, driven by advances in computational power and the availability of large datasets, revolutionized AI by enabling models to learn hierarchical representations of data. Key milestones in the evolution of AI models include:
- 1950s–1960s: Early AI research focused on symbolic reasoning and problem-solving, with models like the Logic Theorist and General Problem Solver.
- 1980s: The rise of expert systems and machine learning algorithms, such as backpropagation for training neural networks.
- 1990s: Support vector machines and ensemble methods gained popularity for their effectiveness in classification tasks.
- 2000s: The resurgence of neural networks with the introduction of deep learning architectures, such as AlexNet for image recognition.
- 2010s–Present: The development of large-scale models like transformers (e.g., BERT, GPT) and diffusion models, which have enabled breakthroughs in natural language processing, computer vision, and generative AI.
#How It Works
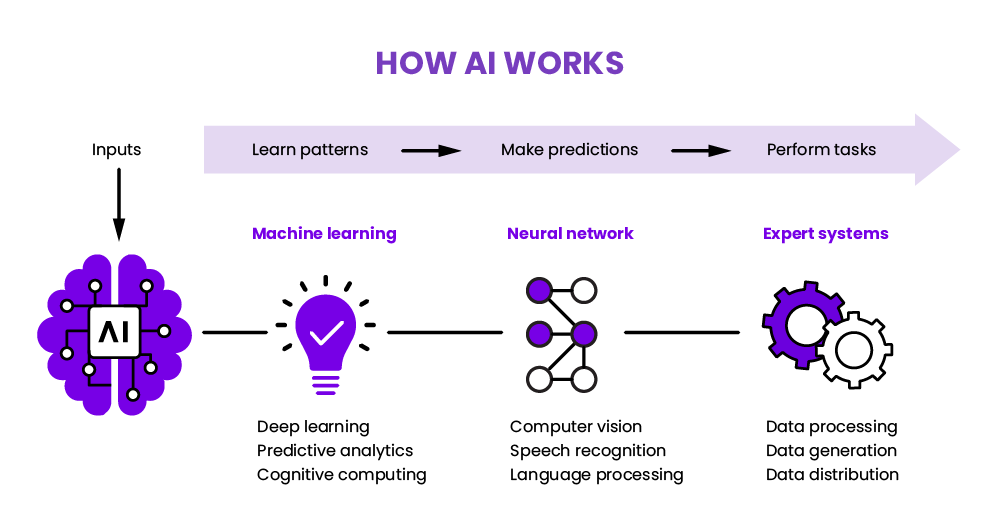
AI models operate through a series of steps that involve data processing, model training, and inference. The process can be broken down into the following stages:
#1. Data Collection and Preprocessing The first step in building an AI model is gathering and preparing the data. Data can be sourced from various channels, including databases, APIs, web scraping, or user inputs. The quality and relevance of the data directly impact the model's performance. Preprocessing involves cleaning, normalizing, and transforming the data to make it suitable for training. Common preprocessing techniques include:
- Data Cleaning: Removing duplicates, handling missing values, and correcting errors.
- Feature Engineering: Selecting or creating relevant features that the model can use for learning.
- Normalization/Standardization: Scaling data to a common range to ensure consistent performance.
- Encoding: Converting categorical data into numerical format (e.g., one-hot encoding).
#2. Model Selection The choice of model depends on the problem type and the nature of the data. For example:
- Supervised Learning: Used for tasks with labeled data, such as classification (e.g., spam detection) or regression (e.g., predicting house prices). Models include logistic regression, random forests, and neural networks.
- Unsupervised Learning: Used for tasks without labeled data, such as clustering (e.g., customer segmentation) or anomaly detection. Models include k-means clustering and principal component analysis (PCA).
- Reinforcement Learning: Used for decision-making tasks where an agent learns by interacting with an environment (e.g., game-playing AI or robotics). Models include Q-learning and deep reinforcement learning.
- Generative Models: Used for creating new data instances, such as text generation or image synthesis. Models include variational autoencoders (VAEs) and generative adversarial networks (GANs).
#3. Training the Model Training involves feeding the preprocessed data into the model and adjusting its parameters to minimize a loss function, which measures the difference between the model's predictions and the actual outcomes. The training process typically uses optimization algorithms like gradient descent to iteratively update the model's weights. Key concepts in training include:
- Loss Function: A metric that quantifies the model's error (e.g., mean squared error for regression, cross-entropy for classification).
- Optimization Algorithm: A method for updating the model's parameters to reduce the loss (e.g., stochastic gradient descent, Adam).
- Hyperparameters: Configurable settings that influence the training process, such as learning rate, batch size, and number of epochs.
- Overfitting vs. Underfitting: Overfitting occurs when the model learns the training data too well, including noise, and fails to generalize to new data. Underfitting occurs when the model is too simple to capture the underlying patterns. Techniques like regularization, dropout, and early stopping are used to mitigate these issues.
#4. Evaluation and Validation After training, the model is evaluated on a separate dataset (the validation or test set) to assess its performance. Common evaluation metrics include:
- Accuracy: The proportion of correct predictions.
- Precision and Recall: Metrics for classification tasks, measuring the model's ability to identify positive instances.
- F1 Score: The harmonic mean of precision and recall.
- Mean Absolute Error (MAE) or Root Mean Squared Error (RMSE): Metrics for regression tasks.
- Confusion Matrix: A table summarizing the model's performance across different classes. Cross-validation techniques, such as k-fold cross-validation, are used to ensure the model's robustness and generalizability.
#5. Deployment and Inference Once validated, the model is deployed into a production environment where it can make predictions on new data. The inference process involves:
- Input Processing: Preparing new data in the same format as the training data.
- Prediction Generation: Using the trained model to generate outputs (e.g., classifications, predictions, or generated content).
- Post-Processing: Applying additional logic to refine the model's outputs (e.g., thresholding for classification, text generation for NLP tasks).
#6. Monitoring and Maintenance AI models require ongoing monitoring to ensure they continue to perform well in real-world conditions. This involves tracking metrics like accuracy, latency, and bias, and retraining the model periodically with new data to adapt to changing environments.
#Important Facts
- Bias and Fairness: AI models can inherit biases present in the training data, leading to unfair or discriminatory outcomes. Techniques like debiasing, fairness-aware training, and diverse dataset collection are used to mitigate these issues.
- Explainability: Many AI models, particularly deep learning models, are often referred to as "black boxes" because their decision-making processes are not easily interpretable. Explainable AI (XAI) techniques aim to make models more transparent and understandable.
- Computational Requirements: Training large AI models, especially deep learning models, requires significant computational resources, including GPUs or TPUs and large-scale distributed systems.
- Data Privacy: AI models trained on sensitive data (e.g., medical records, financial transactions) must comply with privacy regulations like GDPR or HIPAA. Techniques like federated learning and differential privacy are used to protect user data.
- Ethical Considerations: The deployment of AI models raises ethical questions about accountability, transparency, and the potential for misuse (e.g., deepfakes, autonomous weapons). Ethical AI frameworks and guidelines are being developed to address these concerns.
- Transfer Learning: A technique where a pre-trained model is fine-tuned for a specific task, reducing the need for large amounts of task-specific data. This is commonly used in natural language processing and computer vision.
- Edge AI: The deployment of AI models on edge devices (e.g., smartphones, IoT devices) to enable real-time processing and reduce latency. Techniques like model quantization and pruning are used to optimize models for edge deployment.
#Timeline
- Foundational ideas
Core concepts and early methods shape How Do AI Models Work?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does How Do AI Models Work? cover?
Explains how do ai models work?, including the main process, tools, examples, risks, and practical implementation steps.
Why is How Do AI Models Work? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Do, AI, Models before using the ideas in real projects.
#References
- How Do AI Models Work? terminology and background research
- How Do AI Models Work? use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Do case studies, benchmarks, and current industry analysis
Comments
No comments yet. Start the discussion with a useful note.