#Short Answer
Covers facts about machine learning, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
#Infobox
#Overview
Machine learning is a transformative technology that allows computers to learn from data and make data-driven decisions. Unlike traditional programming, where explicit instructions are provided, ML systems use statistical models to identify patterns and relationships within large datasets. This capability enables applications such as predictive analytics, natural language understanding, and computer vision. The field of ML is closely related to statistics, computer science, and data science. It leverages mathematical models, algorithms, and computational power to process vast amounts of data efficiently. As data generation continues to grow exponentially, ML has become a critical tool for extracting meaningful insights and automating complex tasks.
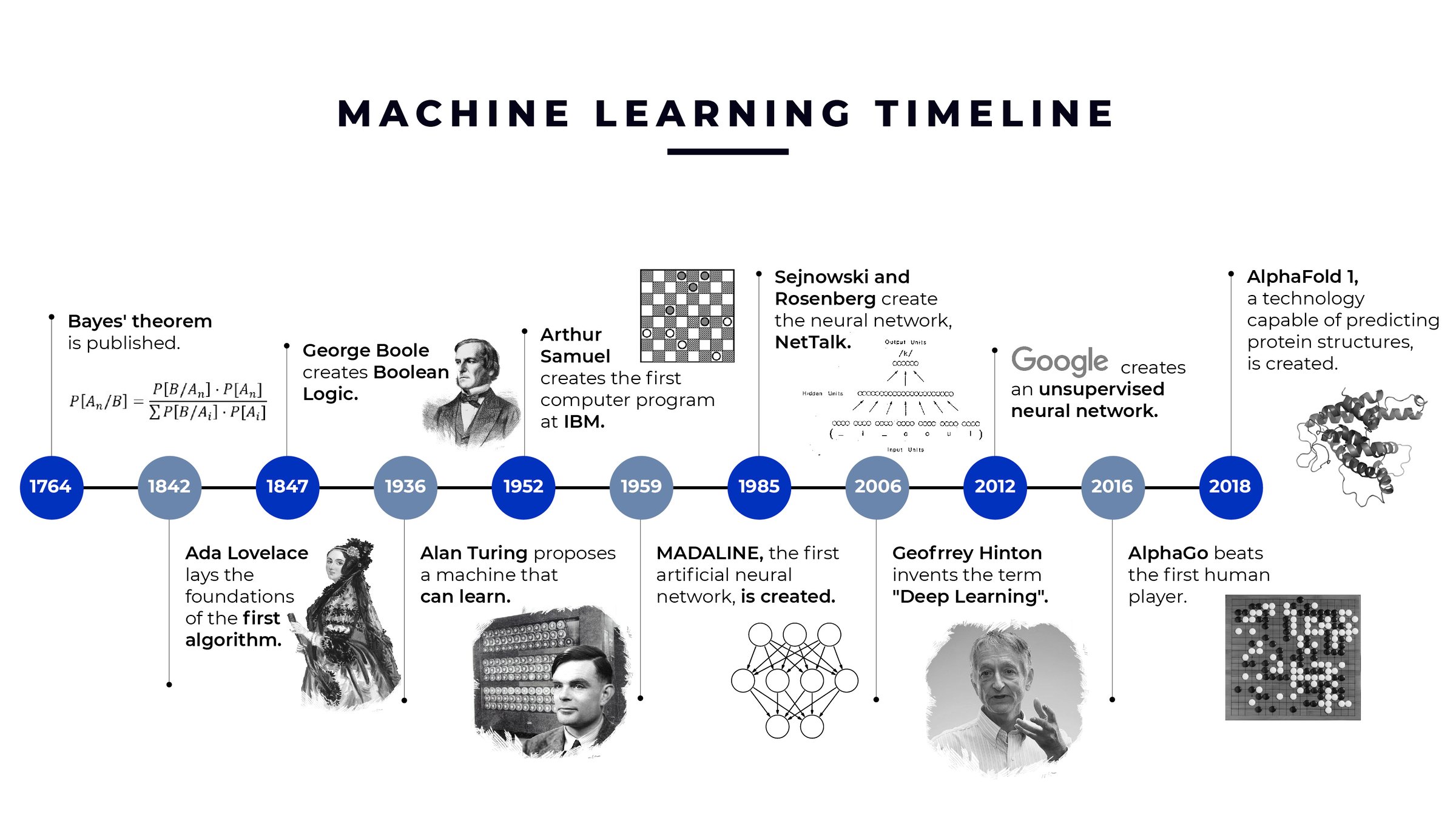
#History / Background
#Early Foundations (1940s–1950s)
The concept of machine learning traces back to the mid-20th century. In 1943, Warren McCulloch and Walter Pitts proposed a mathematical model of artificial neurons, laying the groundwork for neural networks. By 1950, Alan Turing introduced the "Turing Test," which evaluated a machine's ability to exhibit intelligent behavior. In 1952, Arthur Samuel developed a program that could play checkers and improve its performance over time, marking one of the first instances of ML.
#The AI Winter and Revival (1960s–1980s)
During the 1960s and 1970s, ML research faced challenges due to limited computational power and data availability. The field experienced periods of reduced funding and interest, known as the "AI winters." However, advancements in algorithms, such as the development of the perceptron by Frank Rosenblatt in 1958, kept the field alive. The 1980s saw the rise of expert systems and the backpropagation algorithm, which enabled neural networks to learn from errors.
#The Modern Era (1990s–Present)
The 1990s and 2000s witnessed a resurgence in ML, driven by increased computational resources and the availability of large datasets. Key milestones include:
- 1997: IBM's Deep Blue defeated world chess champion Garry Kasparov, showcasing the power of AI.
- 2006: Geoffrey Hinton's work on deep learning revitalized neural networks, leading to breakthroughs in image and speech recognition.
- 2011: IBM Watson won Jeopardy!, demonstrating advanced natural language processing.
- 2012: A deep neural network achieved human-level performance in image classification, winning the ImageNet competition.
- 2016: AlphaGo, developed by DeepMind, defeated a world champion Go player, highlighting the potential of reinforcement learning. Today, ML is integrated into various industries, from healthcare diagnostics to financial forecasting, and continues to evolve with advancements in computing and data science.
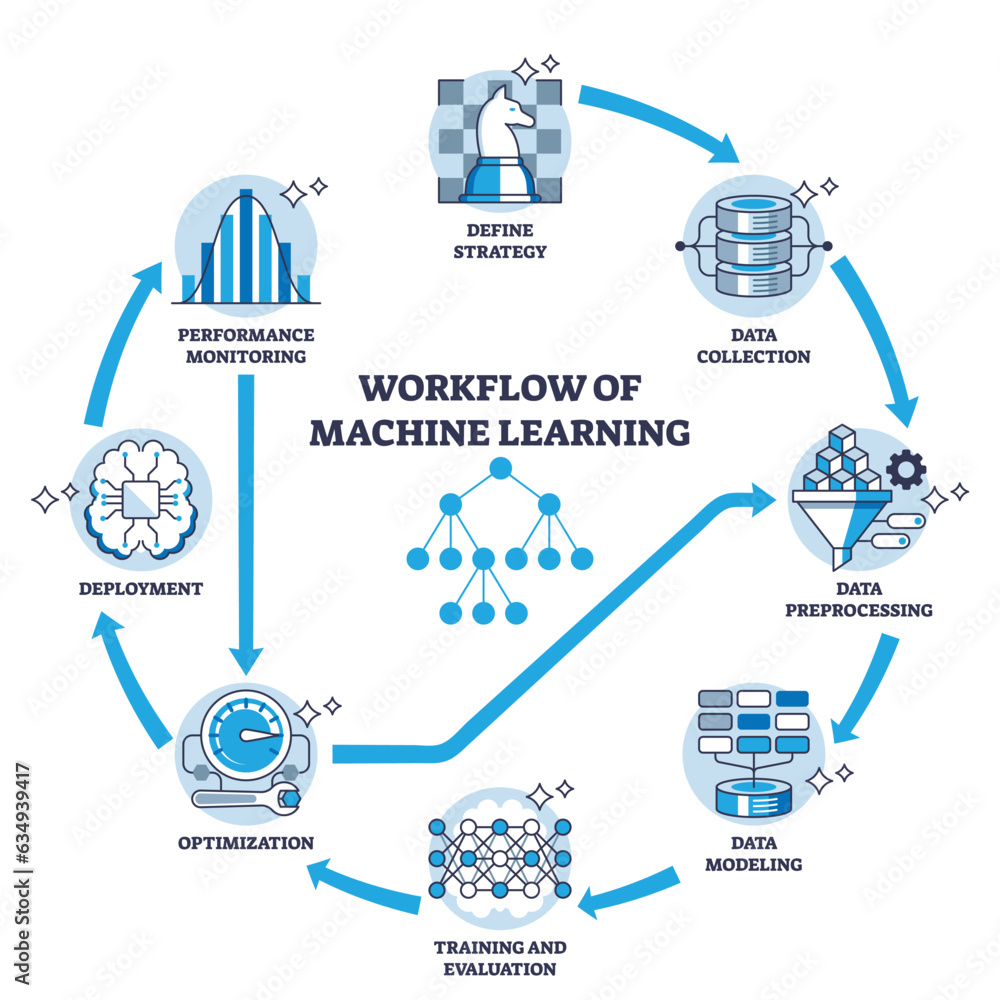
#How It Works
#Core Concepts Machine learning operates on the principle of learning from data. The process involves several key steps:
- Data Collection: Gathering relevant datasets that represent the problem domain.
- Data Preprocessing: Cleaning, normalizing, and transforming data to make it suitable for training.
- Model Selection: Choosing an appropriate algorithm based on the problem type (e.g., classification, regression, clustering).
- Training: Feeding the data into the model to learn patterns and relationships.
- Evaluation: Assessing the model's performance using metrics such as accuracy, precision, recall, or mean squared error.
- Deployment: Implementing the model in real-world applications to make predictions or automate decisions.
#Types of Machine Learning Machine learning can be categorized into several types based on the learning approach:
- Supervised Learning: - The model is trained on labeled data, where input-output pairs are provided. - Used for tasks such as classification (e.g., spam detection) and regression (e.g., predicting house prices). - Common algorithms: Linear regression, logistic regression, support vector machines (SVM), decision trees.
- Unsupervised Learning: - The model learns from unlabeled data, identifying patterns or groupings. - Used for clustering (e.g., customer segmentation) and dimensionality reduction (e.g., principal component analysis). - Common algorithms: K-means clustering, hierarchical clustering, autoencoders.
- Semi-Supervised Learning: - Combines labeled and unlabeled data to improve learning efficiency. - Useful when labeled data is scarce or expensive to obtain.
- Reinforcement Learning (RL): - The model learns by interacting with an environment and receiving rewards or penalties. - Used in robotics, game playing (e.g., AlphaGo), and autonomous systems. - Common algorithms: Q-learning, deep Q-networks (DQN), policy gradients.
- Deep Learning: - A subset of ML that uses artificial neural networks with multiple layers (deep neural networks). - Excels in tasks such as image recognition, natural language processing, and speech synthesis. - Common architectures: Convolutional neural networks (CNNs), recurrent neural networks (RNNs), transformers.
#Key Algorithms and Techniques
- Linear Regression: Predicts continuous outcomes based on linear relationships.
- Logistic Regression: Used for binary classification tasks.
- Decision Trees: Splits data into branches based on feature values to make decisions.
- Support Vector Machines (SVM): Finds the optimal hyperplane to separate classes in high-dimensional space.
- K-Nearest Neighbors (KNN): Classifies data points based on the majority class of their nearest neighbors.
- Neural Networks: Mimic the human brain's structure, enabling complex pattern recognition.
- Ensemble Methods: Combine multiple models to improve performance (e.g., random forests, gradient boosting).
#Important Facts
- Data Dependency: ML models require large, high-quality datasets to perform effectively. Poor data quality can lead to biased or inaccurate predictions.
- Computational Power: Training complex models, especially deep learning models, demands significant computational resources, often requiring GPUs or TPUs.
- Overfitting and Underfitting:
- Overfitting: Occurs when a model learns noise in the training data, performing well on training data but poorly on unseen data.
- Underfitting: Happens when a model is too simple to capture the underlying patterns in the data.
- Bias and Fairness: ML models can inherit biases present in training data, leading to unfair or discriminatory outcomes. Addressing bias is a critical challenge in ML ethics.
- Explainability: Many ML models, particularly deep learning models, are "black boxes," making it difficult to interpret their decisions. Explainable AI (XAI) aims to address this issue.
- Transfer Learning: A technique where a pre-trained model is fine-tuned for a new but related task, reducing the need for large datasets and computational resources.
- Edge Computing: ML models are increasingly deployed on edge devices (e.g., smartphones, IoT devices) to enable real-time processing and reduce latency.
- Ethical Considerations: Issues such as privacy, security, and the societal impact of AI-driven decisions are central to discussions about ML's future.
- Autonomous Systems: ML powers autonomous vehicles, drones, and robotic systems, enabling them to navigate and make decisions in dynamic environments.
- Natural Language Processing (NLP): ML has revolutionized NLP, enabling applications like chatbots, language translation, and sentiment analysis.
#Timeline
- Foundational ideas
Core concepts and early methods shape Facts About Machine Learning.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Facts About Machine Learning cover?
Covers facts about machine learning, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
Why is Facts About Machine Learning important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Facts, About, Machine before using the ideas in real projects.
#References
- Facts About Machine Learning terminology and background research
- Facts About Machine Learning use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Facts case studies, benchmarks, and current industry analysis



Comments
No comments yet. Start the discussion with a useful note.