
#Short Answer
Covers facts about deep learning, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
#Infobox
#Overview
Deep learning is a revolutionary approach within artificial intelligence (AI) that leverages artificial neural networks to process and analyze vast amounts of data. Unlike traditional machine learning, which relies on manually engineered features, deep learning automatically extracts hierarchical representations from raw data through multiple layers of abstraction. This capability has led to breakthroughs in fields such as computer vision, natural language processing (NLP), and autonomous decision-making. The foundation of deep learning lies in the structure of artificial neural networks, which are inspired by the biological neural networks of the human brain. These networks consist of interconnected nodes (neurons) organized into layers: an input layer, one or more hidden layers, and an output layer. Each layer transforms the input data into increasingly abstract representations, enabling the system to learn complex patterns and relationships. One of the defining characteristics of deep learning is its ability to handle unstructured data, such as images, audio, and text, without requiring explicit feature extraction. This has made it particularly effective in applications where data is high-dimensional and difficult to interpret using traditional methods.
#History / Background
The origins of deep learning can be traced back to the mid-20th century, with early concepts rooted in cybernetics and artificial intelligence research. However, the field gained significant traction in the 21st century due to advances in computational power, the availability of large datasets, and algorithmic innovations.
#Early Foundations (1940s–1980s)
- 1943: Warren McCulloch and Walter Pitts proposed the first mathematical model of a neuron, laying the groundwork for artificial neural networks.
- 1958: Frank Rosenblatt developed the Perceptron, an early neural network model capable of learning simple patterns.
- 1960s–1970s: Research into neural networks slowed due to limitations in computational resources and the perceived inefficacy of single-layer models.
#Revival and Challenges (1980s–2000s)
- 1986: Geoffrey Hinton, David Rumelhart, and Ronald Williams introduced backpropagation, a key algorithm for training multi-layer neural networks.
- 1990s: Despite progress, deep learning struggled with the "vanishing gradient problem," where gradients in early layers became too small to effectively update weights during training.
- 2006: Hinton and colleagues demonstrated that pre-training deep belief networks layer by layer could mitigate training difficulties, reigniting interest in deep learning.
#Modern Era
(2010s–Present)
- 2012: A deep convolutional neural network (CNN) called AlexNet won the ImageNet Large Scale Visual Recognition Challenge, achieving unprecedented accuracy in image classification. This event marked a turning point for deep learning in computer vision.
- 2014: The introduction of sequence-to-sequence models and attention mechanisms revolutionized natural language processing, enabling advancements in machine translation and text generation.
- 2017: The Transformer architecture, introduced in the paper "Attention Is All You Need," became a cornerstone for modern NLP models like BERT and GPT, setting new benchmarks in language understanding.
- 2020s: Deep learning continues to evolve with the development of large language models (LLMs), generative adversarial networks (GANs), and reinforcement learning algorithms, expanding its applications across industries.
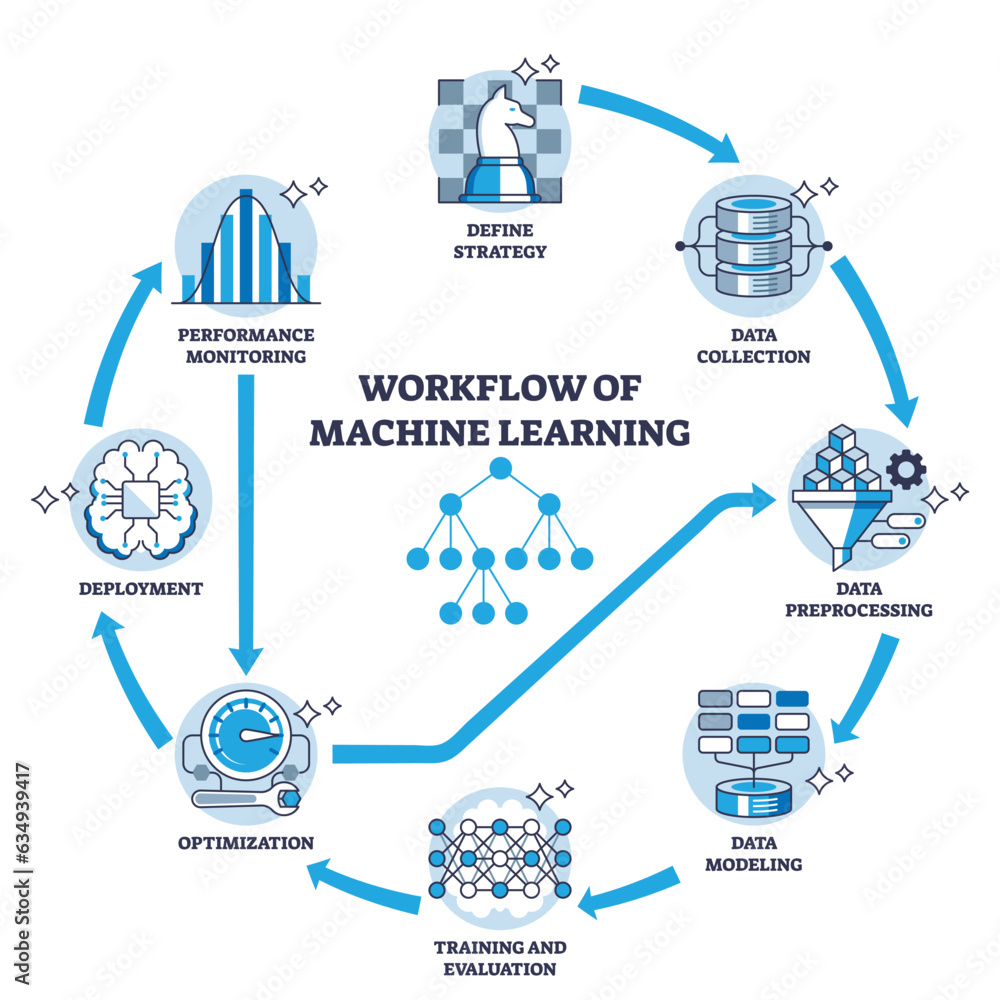
#How It Works
Deep learning operates through the use of artificial neural networks, which are composed of interconnected layers of nodes. The process involves several key steps: data input, feature extraction, pattern recognition, and output generation.
#Neural Network Architecture
A typical deep neural network consists of:
- Input Layer: Receives raw data (e.g., pixels in an image, words in a sentence).
- Hidden Layers: Multiple layers of neurons that progressively transform the input data into abstract representations. These layers can include:
- Convolutional Layers (CNNs): Used primarily in image processing to detect spatial hierarchies of features.
- Recurrent Layers (RNNs, LSTMs, GRUs): Designed for sequential data, such as time series or text, to capture temporal dependencies.
- Fully Connected Layers: Traditional layers where each neuron is connected to every neuron in the previous layer, used for final classification or regression.
- Output Layer: Produces the final prediction or classification based on the learned representations.
#Training Process
Deep learning models are trained using a process called backpropagation, which involves:
- Forward Pass: The input data is passed through the network, and predictions are generated.
- Loss Calculation: A loss function (e.g., cross-entropy for classification, mean squared error for regression) measures the difference between the predicted output and the actual target.
- Backward Pass: The gradients of the loss function with respect to the model's weights are computed using the chain rule of calculus. These gradients indicate how much each weight contributed to the error.
- Weight Update: The weights are adjusted in the opposite direction of the gradients using an optimization algorithm (e.g., stochastic gradient descent, Adam) to minimize the loss.
#Key Techniques
- Activation Functions: Non-linear functions (e.g., ReLU, sigmoid, tanh) introduce non-linearity into the model, enabling it to learn complex patterns.
- Regularization: Techniques like dropout, batch normalization, and L1/L2 regularization prevent overfitting by constraining the model's complexity.
- Transfer Learning: Pre-trained models are fine-tuned on specific tasks, reducing the need for large labeled datasets.
- Attention Mechanisms: Allow models to focus on relevant parts of the input data, improving performance in tasks like machine translation and image captioning.
#Important Facts
#
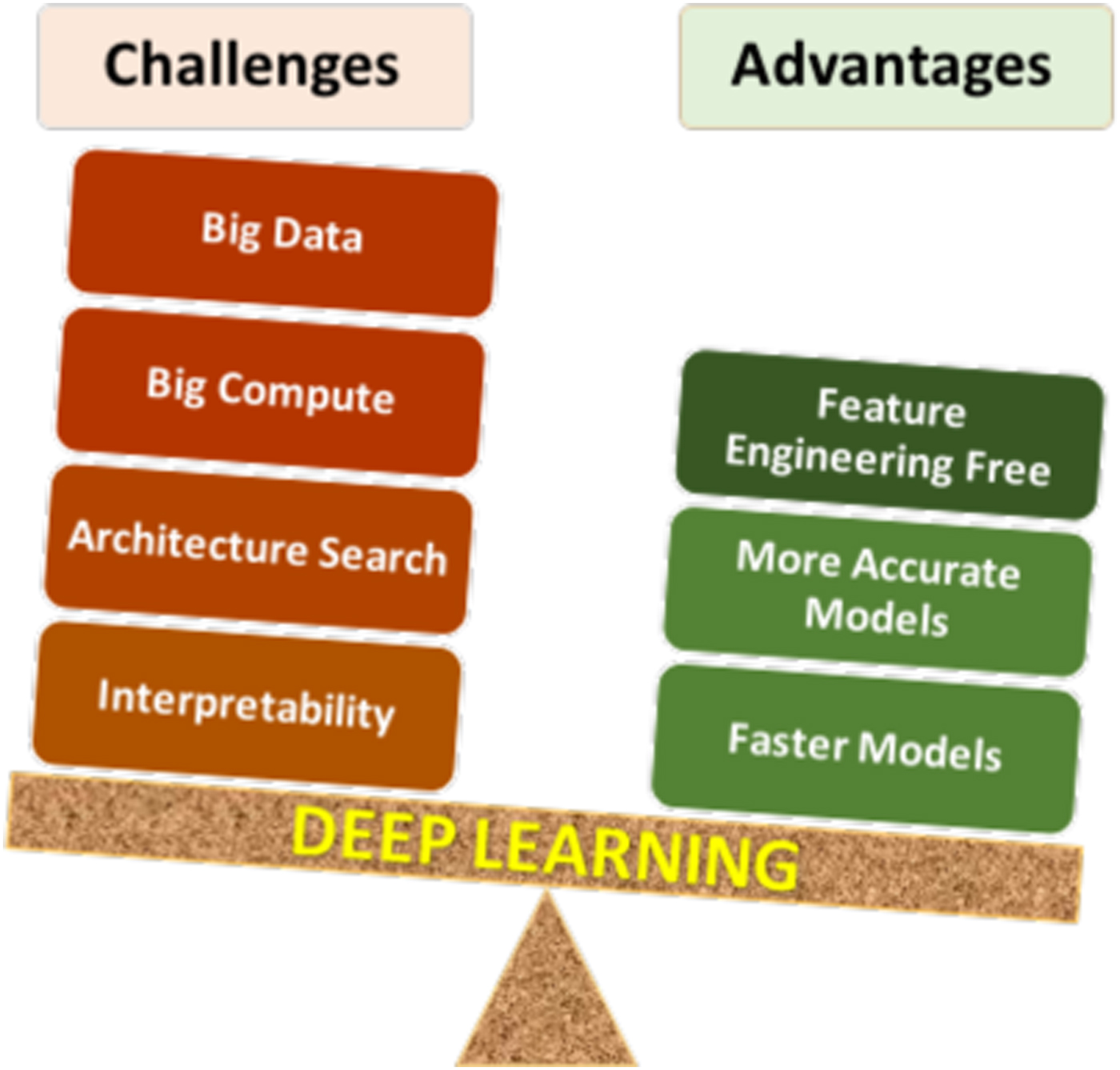
- Data Dependency Deep learning models require vast amounts of labeled data to achieve high accuracy. The quality and quantity of data directly impact the model's performance. For example, ImageNet, a dataset with over 14 million labeled images, has been instrumental in advancing computer vision.
#
- Computational Requirements Training deep learning models is computationally intensive, often requiring specialized hardware such as Graphics Processing Units (GPUs) or Tensor Processing Units (TPUs). Cloud-based solutions like Google Cloud AI, AWS, and Azure provide scalable resources for training large models.
#
- Interpretability Challenges Deep learning models are often referred to as "black boxes" because their decision-making processes are difficult to interpret. Techniques like SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations) are used to explain model predictions.
#
- Transfer Learning Transfer learning allows pre-trained models to be adapted for new tasks with minimal additional training. For instance, a model pre-trained on ImageNet can be fine-tuned for medical image analysis, reducing the need for extensive labeled medical data.
#
- Generative Models Deep learning has enabled the creation of generative models like Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), which can generate realistic images, music, and text. These models have applications in art, entertainment, and data augmentation.
#
- Ethical Considerations The use of deep learning raises ethical concerns, including bias in training data, privacy issues, and the potential for misuse in deepfake technology. Addressing these challenges requires robust ethical frameworks and regulatory oversight.
#
- Hardware Advancements The development of specialized hardware, such as NVIDIA's CUDA cores and Google's TPUs, has accelerated the training and deployment of deep learning models. These advancements have made deep learning more accessible to researchers and businesses.
#
- Open-Source Frameworks The availability of open-source frameworks like TensorFlow, PyTorch, and Keras has democratized deep learning, enabling developers worldwide to build and deploy models without extensive expertise in the underlying mathematics.
#Timeline
- Foundational ideas
Core concepts and early methods shape Facts About Deep Learning.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Facts About Deep Learning cover?
Covers facts about deep learning, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
Why is Facts About Deep Learning important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Facts, About, Deep before using the ideas in real projects.
#References
- Facts About Deep Learning terminology and background research
- Facts About Deep Learning use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Facts case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.