#Short Answer
Covers exploring the basics of deep learning, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
#Infobox
#Overview
Deep learning is a transformative branch of artificial intelligence (AI) that mimics the structure and function of the human brain through artificial neural networks. These networks consist of interconnected layers of nodes (neurons), where each layer extracts and transforms features from the input data, enabling the system to learn complex patterns autonomously. The term "deep" refers to the multiple hidden layers in these networks, which allow for hierarchical feature extraction—from low-level details (e.g., edges in images) to high-level abstractions (e.g., object recognition). The power of deep learning lies in its ability to process vast amounts of unstructured data (e.g., images, text, audio) without manual feature engineering, a task that traditional machine learning methods often require. This capability has led to breakthroughs in fields such as healthcare (e.g., medical imaging analysis), finance (e.g., fraud detection), and autonomous systems (e.g., self-driving cars). The scalability and flexibility of deep learning models make them indispensable in modern AI applications.
#History / Background
#Early Foundations (1940s–1980s)
The conceptual roots of deep learning trace back to the 1940s with the introduction of the perceptron by Frank Rosenblatt, a simplified model of a biological neuron. However, early neural networks were limited by computational constraints and lacked efficient training algorithms. In the 1960s and 1970s, researchers like Marvin Minsky and Seymour Papert highlighted the limitations of single-layer perceptrons, leading to a decline in interest during the "AI winter" of the 1970s.
#Revival and Breakthroughs (1980s–2000s)
The resurgence of neural networks began in the 1980s with the development of backpropagation, an algorithm that efficiently trains multi-layer networks by adjusting weights based on error gradients. Geoffrey Hinton, David Rumelhart, and Ronald Williams demonstrated its effectiveness in 1986, paving the way for deeper architectures. However, practical applications were still hindered by limited computational power and insufficient data.
#The Deep Learning Revolution (2000s–Present)
The modern deep learning era took off in the 2000s, driven by three key factors:
- Big Data: The explosion of digital data (e.g., images, text) provided the fuel for training large-scale models.
- Computational Power: Advances in Graphics Processing Units (GPUs) enabled parallel processing, drastically reducing training times.
- Algorithmic Innovations: Breakthroughs like convolutional neural networks (CNNs) for image processing (e.g., AlexNet in 2012) and recurrent neural networks (RNNs) for sequential data (e.g., Long Short-Term Memory or LSTM networks) revolutionized the field. Landmark achievements include:
- 2012: AlexNet wins the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), outperforming traditional methods by a significant margin.
- 2016: AlphaGo defeats a world champion Go player, showcasing deep learning's potential in complex decision-making.
- 2020s: Large language models (e.g., GPT-3, PaLM) demonstrate near-human performance in natural language understanding and generation.
#How It Works
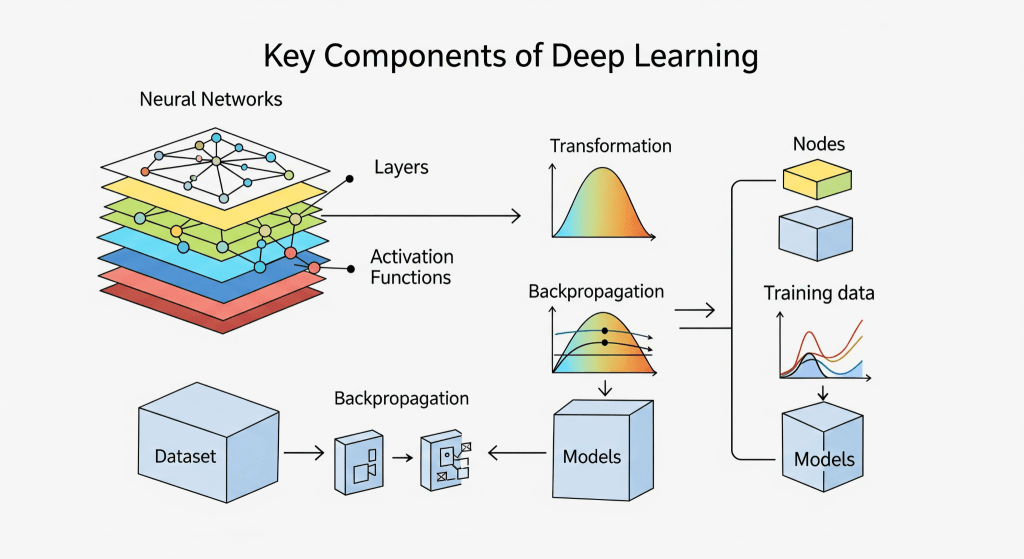
#Neural Network Architecture
A deep learning model is composed of an input layer, one or more hidden layers, and an output layer. Each layer consists of neurons that perform weighted summations of inputs, followed by activation functions (e.g., ReLU, Sigmoid) to introduce non-linearity.
Key Components:
- Layers:
- Input Layer: Receives raw data (e.g., pixel values of an image).
- Hidden Layers: Extract features hierarchically. Common types include:
- Convolutional Layers (CNNs): Specialized for spatial data (e.g., images), using filters to detect patterns like edges or textures.
- Recurrent Layers (RNNs/LSTMs): Designed for sequential data (e.g., time series, text), retaining memory of previous inputs.
- Fully Connected Layers: Traditional dense layers where each neuron connects to every neuron in the next layer.
- Output Layer: Produces the final prediction (e.g., class probabilities in classification tasks).
- Activation Functions: - Introduce non-linearity, enabling the network to learn complex relationships. Examples:
- ReLU (Rectified Linear Unit): Outputs the input directly if positive, else zero (common in hidden layers).
- Sigmoid: Squashes outputs between 0 and 1 (used in binary classification).
- Softmax: Converts outputs into probability distributions (used in multi-class classification).
- Loss Functions: - Measure the difference between predicted and actual outputs. Examples:
- Mean Squared Error (MSE): Used for regression tasks.
- Cross-Entropy Loss: Common in classification tasks, penalizing incorrect predictions heavily.
- Optimization Algorithms: - Adjust the network's weights to minimize the loss function. Popular methods include:
- Stochastic Gradient Descent (SGD): Updates weights iteratively using small batches of data.
- Adam: An adaptive optimizer that combines momentum and adaptive learning rates.
#Training Process
- Forward Propagation: Input data is passed through the network, generating predictions.
- Loss Calculation: The difference between predictions and true labels is computed using the loss function.
- Backpropagation: The gradient of the loss with respect to each weight is calculated, and weights are updated to reduce the loss.
- Iteration: Steps 1–3 repeat over multiple epochs until the model converges (i.e., loss stabilizes).
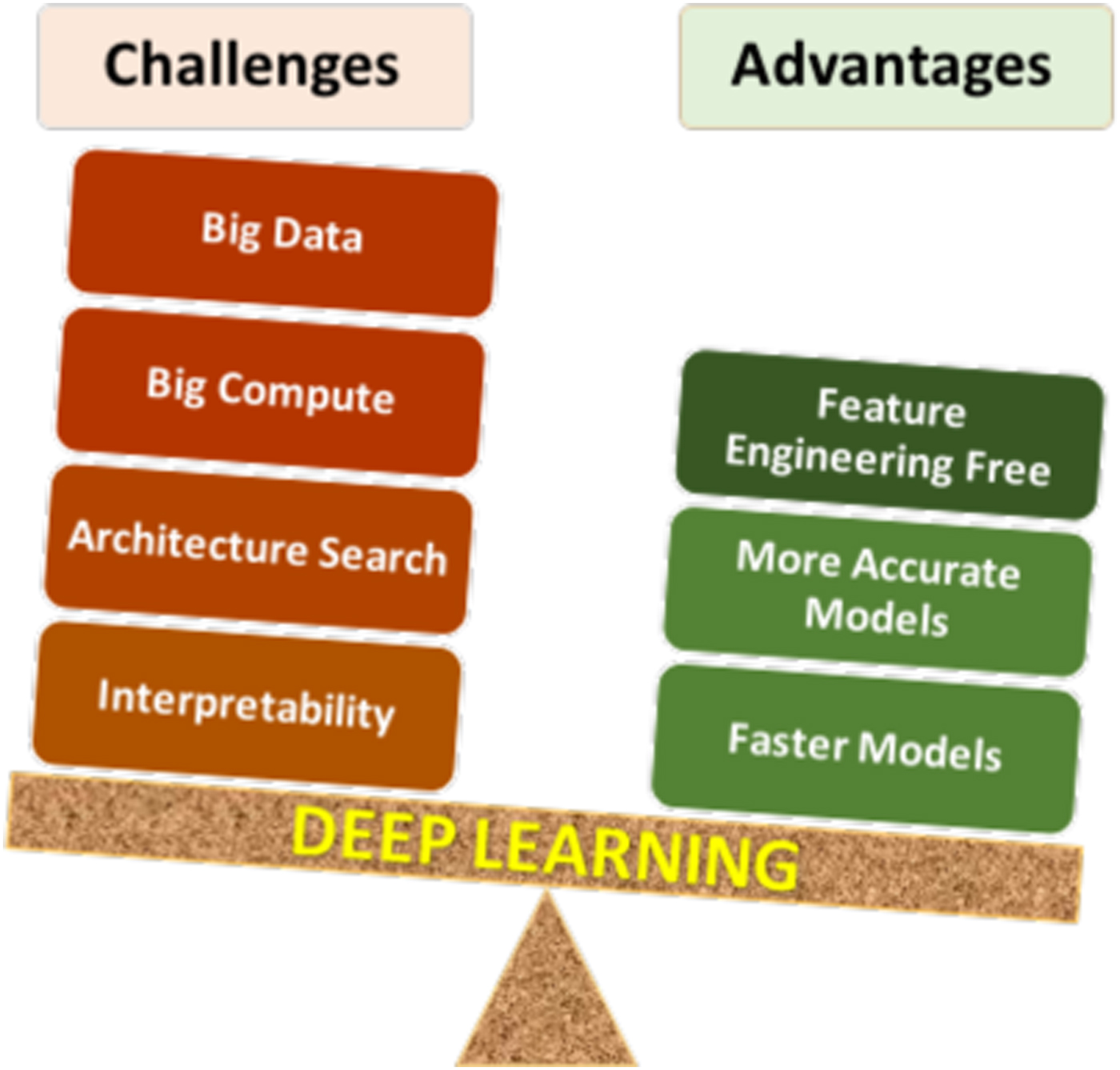
#Challenges in Training
- Vanishing Gradients: Gradients become too small during backpropagation, hindering learning in deep networks. Solutions include skip connections (e.g., ResNet) or batch normalization.
- Overfitting: The model memorizes training data but performs poorly on unseen data. Mitigated by regularization techniques (e.g., dropout, L2 regularization) or data augmentation.
- Computational Cost: Training large models requires significant resources. Techniques like transfer learning (using pre-trained models) and distributed training (e.g., using multiple GPUs) address this.
#Important Facts
- Hierarchical Feature Learning: Deep learning models automatically learn feature hierarchies, where higher layers represent more abstract concepts (e.g., a CNN might first detect edges, then shapes, then objects).
- Data Hunger: Deep learning models typically require large datasets to generalize well. For example, ImageNet contains over 14 million labeled images.
- Transfer Learning: Pre-trained models (e.g., VGG, BERT) can be fine-tuned for specific tasks, reducing the need for extensive training data.
- Interpretability: Deep learning models are often "black boxes," making it challenging to explain their decisions. Techniques like SHAP values or LIME aim to improve interpretability.
- Ethical Concerns: Bias in training data can lead to discriminatory outcomes (e.g., facial recognition systems performing poorly on certain demographics).
- Energy Consumption: Training large models (e.g., GPT-3) consumes significant energy, raising sustainability concerns.
- Hardware Acceleration: GPUs, TPUs (Tensor Processing Units), and specialized hardware (e.g., neuromorphic chips) are critical for efficient training.
#Timeline
- Foundational ideas
Core concepts and early methods shape Exploring the Basics of Deep Learning.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Exploring the Basics of Deep Learning cover?
Covers exploring the basics of deep learning, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
Why is Exploring the Basics of Deep Learning important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Exploring, Basics, Deep before using the ideas in real projects.
#References
- Exploring the Basics of Deep Learning terminology and background research
- Exploring the Basics of Deep Learning use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Exploring case studies, benchmarks, and current industry analysis



Comments
No comments yet. Start the discussion with a useful note.