
#Short Answer
Covers deep learning for dummies: a beginner’s overview, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
#Infobox
#Overview
Deep Learning For Dummies serves as an introductory resource for individuals seeking to understand the core principles of deep learning without requiring advanced mathematical or programming expertise. The book breaks down intricate concepts into digestible chapters, covering topics such as neural network architectures, training methodologies, and real-world applications. It emphasizes practical examples and step-by-step explanations to demystify the field, making it accessible to a broad audience, including students, hobbyists, and professionals exploring AI-driven technologies. The book is part of the For Dummies series, known for its user-friendly approach to complex subjects. It bridges the gap between theoretical knowledge and hands-on implementation, ensuring readers gain both conceptual clarity and functional skills. Whether used as a self-study guide or a supplementary text, Deep Learning For Dummies aims to equip beginners with the foundational tools needed to navigate the rapidly evolving landscape of artificial intelligence.
#History / Background
#Origins of Deep Learning Deep learning traces its roots to the mid-20th century, with early concepts emerging from the study of artificial neural networks (ANNs). The term "deep learning" itself gained prominence in the 2010s, driven by breakthroughs in computational power, large-scale datasets, and algorithmic advancements. Key milestones include:
- 1943: Warren McCulloch and Walter Pitts proposed the first mathematical model of a neural network, laying the groundwork for artificial intelligence.
- 1958: Frank Rosenblatt developed the Perceptron, an early form of a neural network capable of simple pattern recognition.
- 1986: Geoffrey Hinton, David Rumelhart, and Ronald Williams introduced backpropagation, a critical algorithm for training multi-layer neural networks.
- 2006: Hinton and collaborators published a seminal paper on deep belief networks, reigniting interest in deep learning by demonstrating its potential for unsupervised feature learning.
- 2012: A deep learning model won the ImageNet Large Scale Visual Recognition Challenge, achieving unprecedented accuracy in image classification and catapulting deep learning into mainstream AI research.
#Evolution of Deep Learning For Dummies The For Dummies series has long been a staple for simplifying complex topics across various fields. As deep learning gained traction in academia and industry, the need for accessible educational resources grew. Deep Learning For Dummies was published in 2020 by Wiley, aligning with the increasing demand for AI literacy among non-experts. The book reflects the series' signature style—breaking down jargon, providing analogies, and offering actionable insights—while addressing the unique challenges of deep learning, such as computational requirements and ethical considerations.
#How It Works
#Core Concepts Deep Learning For Dummies introduces readers to the following foundational concepts:
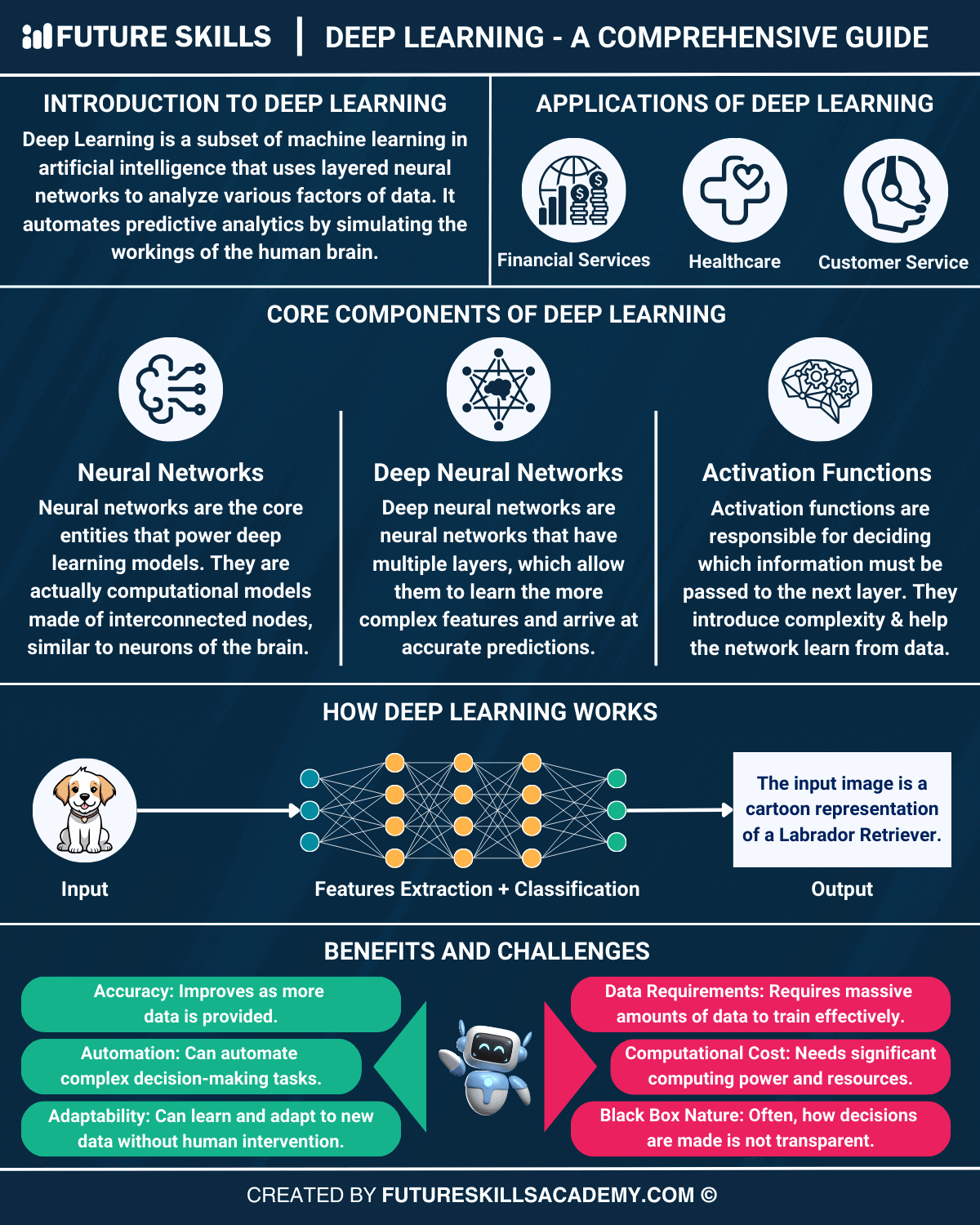
- Neural Networks:
- Structure: Inspired by the human brain, neural networks consist of interconnected nodes (neurons) organized into layers: input, hidden, and output.
- Activation Functions: Functions like ReLU (Rectified Linear Unit) and sigmoid introduce non-linearity, enabling networks to model complex relationships.
- Weights and Biases: Parameters adjusted during training to minimize prediction errors.
- Training Process:
- Forward Propagation: Data flows through the network, generating predictions.
- Loss Function: Measures the difference between predictions and actual values (e.g., mean squared error for regression, cross-entropy for classification).
- Backpropagation: An algorithm that calculates gradients of the loss function with respect to each weight, enabling optimization via gradient descent.
- Optimization: Techniques like stochastic gradient descent (SGD) and Adam adjust weights to improve model performance.
- Deep Learning Architectures:
- Feedforward Neural Networks (FNNs): The simplest form, used for tasks like regression and classification.
- Convolutional Neural Networks (CNNs): Specialized for image processing, leveraging convolutional layers to detect spatial hierarchies.
- Recurrent Neural Networks (RNNs): Designed for sequential data (e.g., time series, text), using loops to retain memory.
- Transformers: Introduced in 2017, these architectures (e.g., BERT, GPT) revolutionized natural language processing (NLP) by using self-attention mechanisms.
- Key Techniques:
- Regularization: Methods like dropout and L1/L2 regularization prevent overfitting by penalizing complex models.
- Hyperparameter Tuning: Adjusting parameters (e.g., learning rate, batch size) to optimize performance.
- Transfer Learning: Leveraging pre-trained models (e.g., ResNet, BERT) to accelerate training on new tasks.
#Practical Applications The book illustrates how deep learning is applied across industries:
- Computer Vision: Object detection, facial recognition, and medical imaging.
- Natural Language Processing (NLP): Sentiment analysis, machine translation, and chatbots.
- Autonomous Systems: Self-driving cars and robotics.
- Healthcare: Drug discovery, disease diagnosis, and personalized medicine.
#Important Facts
- Computational Requirements: Deep learning models often require significant computational resources, including GPUs or TPUs, to train efficiently. Cloud platforms like AWS, Google Cloud, and Azure provide scalable solutions for resource-intensive tasks.
- Data Dependency: Deep learning thrives on large datasets. The quality and quantity of data directly impact model performance. Techniques like data augmentation (e.g., image rotation, text paraphrasing) help mitigate data scarcity.
- Ethical Considerations:
- Bias and Fairness: Models trained on biased data may perpetuate or amplify societal prejudices.
- Privacy: Handling sensitive data (e.g., medical records) requires adherence to regulations like GDPR.
- Explainability: "Black box" models challenge transparency, prompting research into interpretable AI (e.g., SHAP values, LIME).
- Hardware Advancements: The rise of deep learning is closely tied to hardware innovations, such as NVIDIA's CUDA-enabled GPUs and Google's Tensor Processing Units (TPUs), which accelerate matrix operations critical to neural networks.
- Open-Source Ecosystem: Frameworks like TensorFlow, PyTorch, and Keras democratize deep learning by providing user-friendly APIs. These tools enable rapid prototyping and deployment of models.
#Timeline
- Foundational ideas
Core concepts and early methods shape Deep Learning for Dummies: a Beginner’s Overview.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Deep Learning for Dummies: a Beginner’s Overview cover?
Covers deep learning for dummies: a beginner’s overview, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
Why is Deep Learning for Dummies: a Beginner’s Overview important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Deep, Learning, Beginner before using the ideas in real projects.
#References
- Deep Learning for Dummies: a Beginner’s Overview terminology and background research
- Deep Learning for Dummies: a Beginner’s Overview use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Deep case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.