#Short Answer
Explains What Is Unsupervised Learning, including the core definition, how it works, practical examples, and limitations.
#Infobox
#Overview
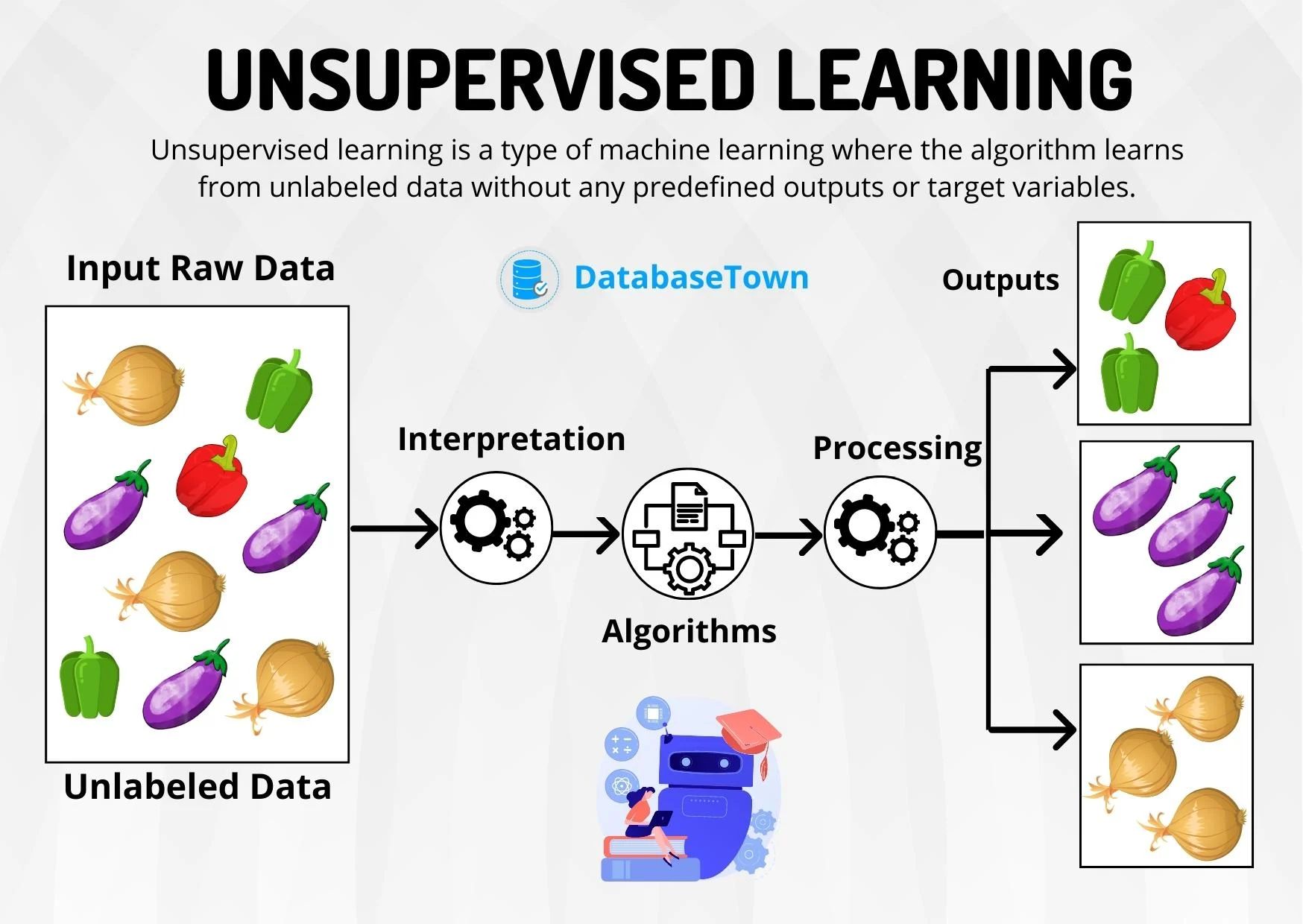
Unsupervised learning is a foundational branch of machine learning that operates on the principle of discovering hidden structures in unlabeled data. Unlike supervised learning, which relies on input-output pairs for training, unsupervised learning algorithms infer relationships directly from the data’s inherent properties. This approach is particularly valuable in scenarios where labeled data is scarce, expensive to obtain, or nonexistent, making it indispensable for exploratory data analysis, pattern recognition, and preprocessing tasks in data science workflows. The core objective of unsupervised learning is to model the underlying distribution of the data to extract meaningful insights. This can manifest in various forms, such as grouping similar data points into clusters (clustering), reducing the number of features while preserving essential information (dimensionality reduction), or identifying anomalies that deviate from expected patterns (anomaly detection). By leveraging statistical techniques and optimization algorithms, unsupervised learning enables machines to uncover latent structures that may not be immediately apparent to human analysts.
#History / Background
The conceptual roots of unsupervised learning trace back to early statistical methods and pattern recognition techniques developed in the mid-20th century. One of the earliest influential works was factor analysis, introduced by Charles Spearman in 1904, which aimed to identify underlying variables (factors) that explain observed correlations in data. This laid the groundwork for dimensionality reduction techniques that remain central to unsupervised learning today. In the 1960s and 1970s, clustering algorithms such as k-means, proposed by Stuart Lloyd in 1957 and later popularized by James MacQueen in 1967, gained prominence as practical tools for grouping data. Around the same time, hierarchical clustering emerged as a method to organize data into nested clusters, providing a hierarchical view of relationships. The 1980s saw the development of self-organizing maps (SOMs) by Teuvo Kohonen, which combined neural networks with clustering to visualize high-dimensional data in lower dimensions. The advent of principal component analysis (PCA) in the early 20th century, formalized by Harold Hotelling in 1933, further solidified unsupervised learning’s role in data analysis. PCA’s ability to transform data into a lower-dimensional space while retaining variance made it a cornerstone for feature extraction and noise reduction. In the 21st century, advances in deep learning have expanded unsupervised learning’s capabilities, with autoencoders and generative adversarial networks (GANs) enabling more sophisticated pattern discovery and data generation.
#How It Works
Unsupervised learning algorithms operate by identifying patterns or structures in data without explicit guidance. The process typically involves the following steps:
#
- Data Collection and Preprocessing - Gather unlabeled data, which may include numerical, categorical, or mixed-type features. - Preprocess the data by normalizing features, handling missing values, and encoding categorical variables to ensure compatibility with the algorithm.
#
- Algorithm Selection - Choose an unsupervised learning technique based on the problem’s goals:
- Clustering: Grouping similar data points (e.g., k-means, DBSCAN, hierarchical clustering).
- Dimensionality Reduction: Simplifying data by reducing the number of features (e.g., PCA, t-SNE, UMAP).
- Anomaly Detection: Identifying outliers (e.g., Isolation Forest, One-Class SVM).
- Association Rule Learning: Discovering relationships between variables (e.g., Apriori algorithm).
#
- Model Training - The algorithm processes the data to identify patterns. For example:
- K-Means: Partitions data into k clusters by minimizing the variance within each cluster.
- PCA: Projects data onto orthogonal axes (principal components) that capture the most variance.
- Autoencoders: Neural networks that compress data into a latent space and reconstruct it, learning efficient representations.
#
- Pattern Interpretation - Analyze the output to derive insights. For clustering, this might involve visualizing clusters or interpreting their characteristics. For dimensionality reduction, it could mean examining the transformed features for interpretability.
#
- Evaluation and Validation - Assess the model’s performance using metrics appropriate for the task:
- Clustering: Silhouette score, Davies-Bouldin index, or elbow method for k-means.
- Dimensionality Reduction: Reconstruction error (for autoencoders) or explained variance (for PCA).
- Anomaly Detection: Precision, recall, or F1-score for labeled anomaly datasets.
#
- Deployment and Iteration - Deploy the model in applications such as customer segmentation, image compression, or fraud detection. - Iterate by refining parameters, trying alternative algorithms, or incorporating domain knowledge to improve results.
#Important Facts
- No Labels Required: Unsupervised learning does not rely on pre-labeled data, making it suitable for exploratory analysis where labels are unavailable or costly to obtain.
- Exploratory Nature: It is often used in the initial stages of data analysis to uncover hidden patterns before applying supervised methods.
- Scalability: Many unsupervised algorithms, such as k-means, scale efficiently to large datasets, though some (e.g., hierarchical clustering) may struggle with high-dimensional data.
- Interpretability Challenges: The lack of ground truth labels can make it difficult to evaluate the "correctness" of results, requiring domain expertise for validation.
- Applications Across Domains:
- Healthcare: Identifying patient subgroups based on medical records.
- Finance: Detecting fraudulent transactions through anomaly detection.
- Marketing: Segmenting customers for targeted campaigns.
- Genomics: Clustering gene expression data to identify biological patterns.
- Hybrid Approaches: Unsupervised learning often complements supervised learning. For example, dimensionality reduction (e.g., PCA) can be used as a preprocessing step for supervised models to improve performance.
#Timeline
- Foundational ideas
Core concepts and early methods shape What Is Unsupervised Learning?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does What Is Unsupervised Learning? cover?
Explains What Is Unsupervised Learning, including the core definition, how it works, practical examples, and limitations.
Why is What Is Unsupervised Learning? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Unsupervised, Learning, AI before using the ideas in real projects.
#References
- What Is Unsupervised Learning? terminology and background research
- What Is Unsupervised Learning? use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Unsupervised case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.