#Short Answer
Explains What Is Supervised Learning, including the core definition, how it works, practical examples, and limitations.
#Infobox
#Overview
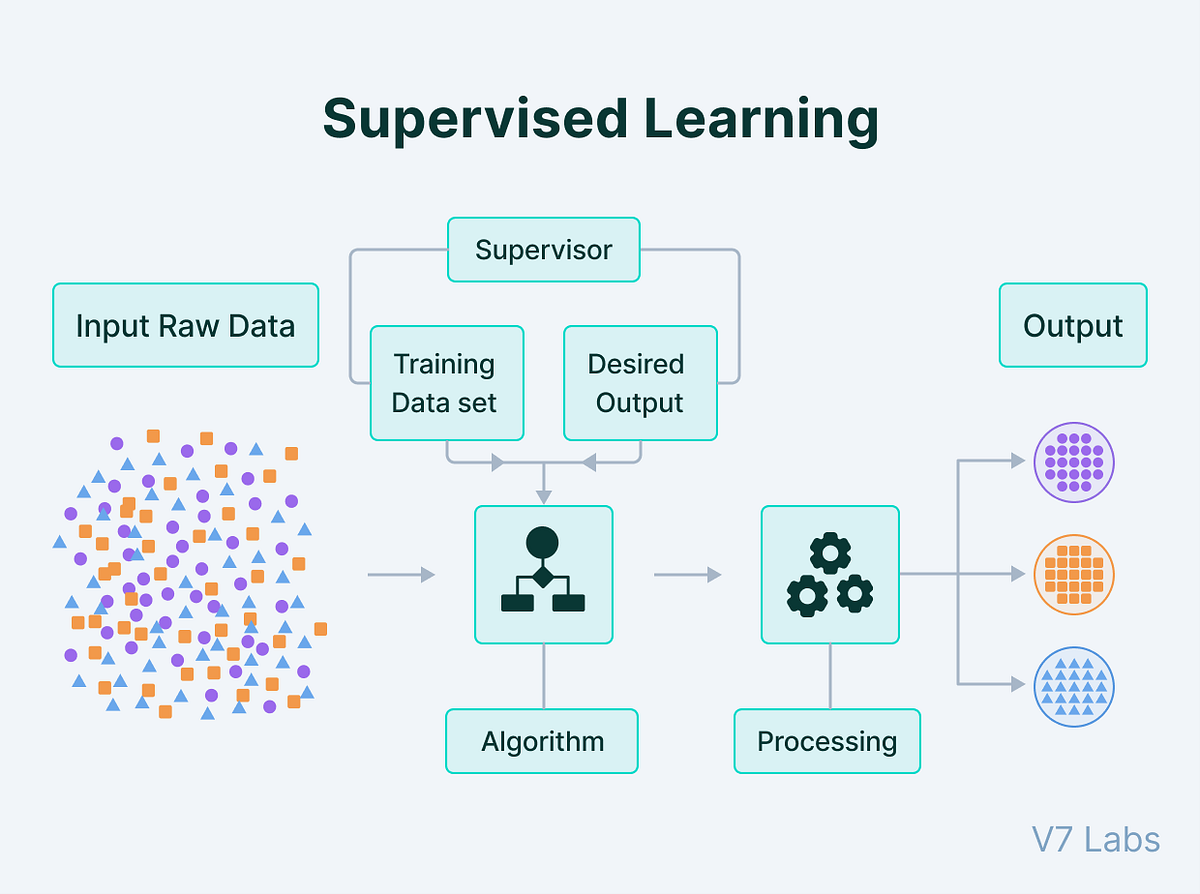
Supervised learning is a foundational paradigm in machine learning where the model is trained on a dataset containing input-output pairs. Unlike unsupervised learning, which discovers patterns in unlabeled data, supervised learning relies on explicit supervision—correct answers provided during training. This approach enables the model to learn the relationship between inputs and outputs, allowing it to generalize and make predictions on new, unseen data. The process begins with a labeled dataset, where each data point consists of an input feature vector and a corresponding output label. The model, often a neural network, decision tree, or regression algorithm, adjusts its internal parameters to minimize the difference between its predictions and the true labels. Once trained, the model can classify new inputs into predefined categories (classification) or predict continuous values (regression). Supervised learning is widely used across industries, including healthcare for disease diagnosis, finance for fraud detection, and marketing for customer segmentation. Its effectiveness depends on the quality and representativeness of the training data, as well as the choice of algorithm and hyperparameters.
#History / Background
The origins of supervised learning trace back to early statistical methods and the development of linear regression in the 19th century. However, the formalization of supervised learning as a machine learning paradigm emerged in the mid-20th century, alongside advancements in computational power and data availability. In the 1950s and 1960s, researchers like Arthur Samuel explored machine learning through programs that improved with experience, laying the groundwork for supervised learning. The 1980s and 1990s saw significant progress with the introduction of algorithms such as decision trees, support vector machines (SVMs), and neural networks. These methods demonstrated the potential of supervised learning to solve complex real-world problems. The rise of big data in the 21st century further accelerated the field, enabling the training of large-scale models on vast labeled datasets. Innovations like deep learning, which uses multi-layered neural networks, have expanded the capabilities of supervised learning, particularly in areas like image recognition, natural language processing, and autonomous systems.
#How It Works
#Training Process
Supervised learning operates through a structured training process involving the following key steps:
- Data Collection and Preparation A labeled dataset is curated, where each input feature (e.g., pixel values in an image, words in a text) is paired with a known output label (e.g., "cat," "dog," or a numerical value like house price). The dataset is typically split into training, validation, and test sets to evaluate model performance.
- Model Selection An appropriate algorithm is chosen based on the problem type:
- Classification: Predicts discrete labels (e.g., spam vs. not spam).
- Regression: Predicts continuous values (e.g., stock prices). Common algorithms include:
- Linear Regression: Models linear relationships between inputs and outputs.
- Logistic Regression: Used for binary classification.
- Decision Trees: Splits data into branches based on feature values.
- Support Vector Machines (SVMs): Finds optimal hyperplanes to separate classes.
- Neural Networks: Learns complex patterns through layered computations.
- Training the Model The model is trained by feeding it the labeled training data. During training, the algorithm adjusts its parameters (e.g., weights in a neural network) to minimize a loss function, which measures the difference between predicted and actual outputs. Optimization techniques like gradient descent are used to iteratively refine the model.
- Evaluation and Validation The model's performance is assessed using the validation set to tune hyperparameters (e.g., learning rate, tree depth). The test set, which the model has never seen, provides an unbiased evaluation of its generalization ability.
- Prediction Once trained, the model can predict outputs for new, unseen inputs. For example, a supervised learning model trained on historical sales data can predict future sales based on new input features.
#Key Concepts
- Loss Function: Quantifies the error between predictions and true labels (e.g., mean squared error for regression, cross-entropy for classification).
- Overfitting: Occurs when the model memorizes training data but fails to generalize to new data. Techniques like regularization, dropout (in neural networks), and early stopping mitigate this.
- Bias-Variance Tradeoff: Balances model complexity to avoid underfitting (high bias) or overfitting (high variance).
- Feature Engineering: The process of selecting and transforming input features to improve model performance.
#Important Facts
- Dependence on Labeled Data: Supervised learning requires high-quality labeled datasets, which can be expensive and time-consuming to obtain.
- Algorithm Diversity: Different algorithms excel in different scenarios. For instance, SVMs are effective for high-dimensional data, while decision trees handle non-linear relationships well.
- Scalability: Modern supervised learning models, particularly deep learning networks, can scale to massive datasets but require significant computational resources.
- Interpretability vs. Performance: Simpler models (e.g., linear regression) are more interpretable but may underperform compared to complex models (e.g., deep neural networks).
- Ethical Considerations: Biases in training data can lead to biased predictions, raising concerns in applications like hiring, lending, and law enforcement.
- Transfer Learning: Pre-trained models (e.g., BERT for NLP) can be fine-tuned for specific supervised learning tasks, reducing the need for large labeled datasets.
#Timeline
- Foundational ideas
Core concepts and early methods shape What Is Supervised Learning?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does What Is Supervised Learning? cover?
Explains What Is Supervised Learning, including the core definition, how it works, practical examples, and limitations.
Why is What Is Supervised Learning? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Supervised, Learning, AI before using the ideas in real projects.
#References
- What Is Supervised Learning? terminology and background research
- What Is Supervised Learning? use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Supervised case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.