#Short Answer
Explains What Is a GAN (generative Adversarial Network), including the core definition, how it works, practical examples, and limitations.
#Infobox
#Overview
A Generative Adversarial Network (GAN) is a deep learning architecture designed to generate new, synthetic data that closely resembles real-world data. Introduced by Ian Goodfellow and colleagues in 2014, GANs leverage a competitive training process between two neural networks: the generator and the discriminator. The generator’s objective is to produce realistic data samples, while the discriminator’s role is to distinguish between real and fake data. This adversarial dynamic drives both networks to improve iteratively, leading to the generation of highly plausible outputs. GANs have revolutionized fields such as computer vision, natural language processing, and creative AI, enabling applications like image synthesis, text-to-image generation, and video enhancement. Their ability to learn from unlabeled data makes them particularly valuable in scenarios where large datasets are scarce or expensive to obtain.
#History / Background
#Origins and Development The concept of GANs was first introduced in a 2014 paper by Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. The paper, titled "Generative Adversarial Nets", was published on arXiv and laid the foundation for one of the most influential advancements in deep learning. Before GANs, generative models like Variational Autoencoders (VAEs) and Restricted Boltzmann Machines (RBMs) existed but faced limitations in generating high-quality, diverse samples. GANs addressed these shortcomings by introducing an adversarial training mechanism, which proved more effective in producing sharp and realistic outputs.
#Evolution of GANs Since their inception, GANs have undergone significant evolution, with numerous variants developed to address specific challenges:
- DCGAN (Deep Convolutional GAN, 2015): Introduced by Alec Radford et al., DCGANs improved stability and performance by using convolutional layers, making them ideal for image generation.
- WGAN (Wasserstein GAN, 2017): Proposed by Martin Arjovsky et al., WGANs addressed training instability by using the Wasserstein distance as a loss function, leading to more reliable convergence.
- CGAN (Conditional GAN, 2014): Extends GANs by conditioning the generator and discriminator on additional input labels, enabling controlled generation (e.g., generating images of specific classes).
- StyleGAN (2018): Developed by NVIDIA, StyleGAN introduced a style-based generator architecture, allowing for high-resolution image synthesis with fine-grained control over attributes like hair color and facial features.
- CycleGAN (2017): Enables unpaired image-to-image translation, such as converting photographs of horses to zebras without requiring paired training data.
- ProGAN (Progressive GAN, 2017): Gradually increases the resolution of generated images during training, improving detail and stability.
- BigGAN (2018): Scales up GANs to larger architectures, achieving state-of-the-art results in high-fidelity image generation.
#Impact and Adoption GANs have gained widespread adoption in both academia and industry due to their versatility. They are used in:
- Art and Design: Generating paintings, music, and 3D models.
- Healthcare: Synthetic medical imaging for training diagnostic models.
- Entertainment: Deepfake technology and virtual avatars.
- Autonomous Systems: Simulating real-world scenarios for training self-driving cars. Despite their success, GANs also face challenges, including training instability, mode collapse (where the generator produces limited varieties of outputs), and ethical concerns related to misuse in deepfakes.
#How It Works
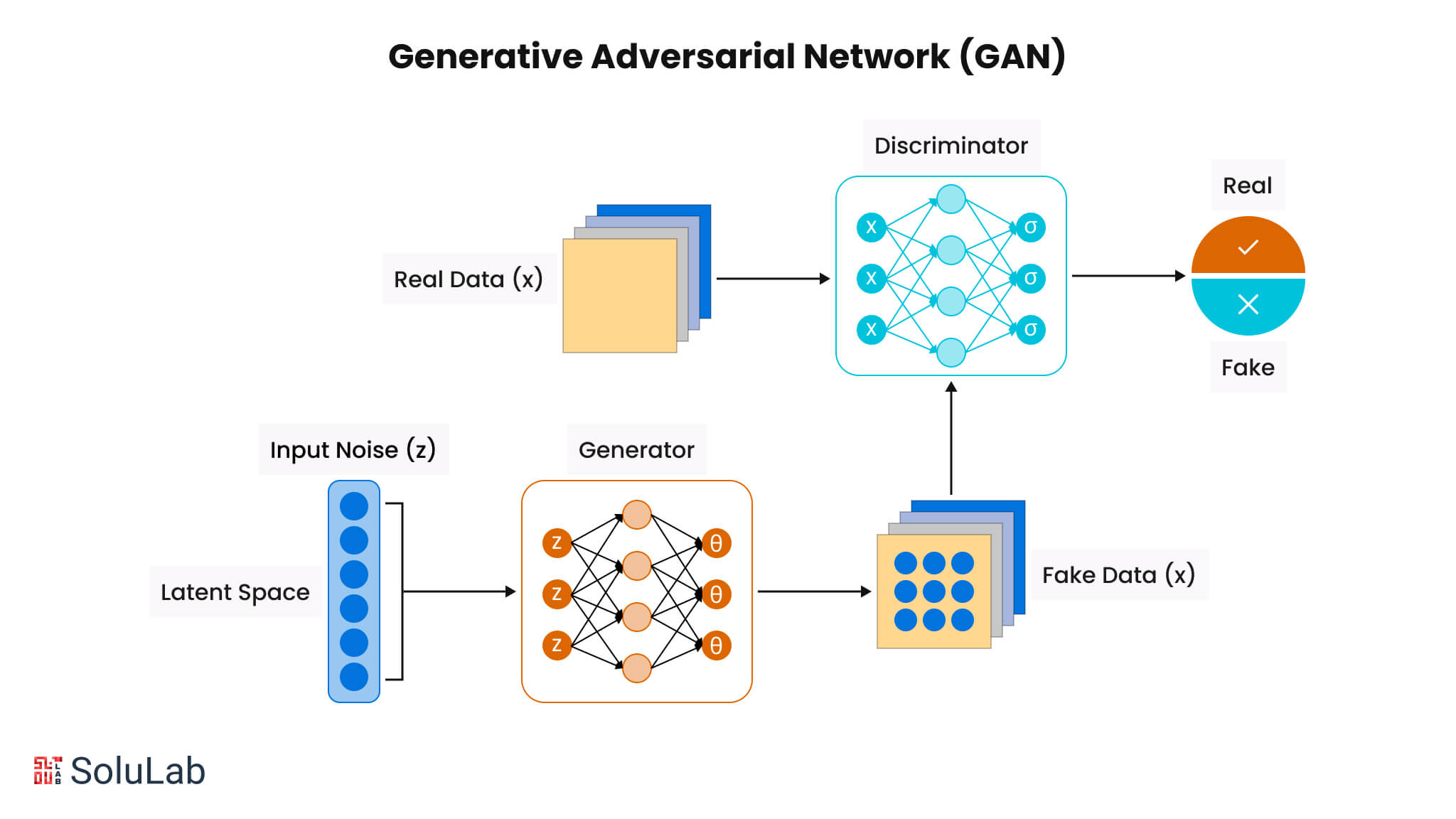
#Core Components A GAN consists of two primary neural networks:
- Generator (G): - Takes random noise (latent vector) as input and transforms it into synthetic data (e.g., an image). - The goal is to produce data that is indistinguishable from real data. - Typically a deconvolutional neural network (DCNN) or transposed convolutional network.
- Discriminator (D): - Acts as a classifier, evaluating whether a given input is real (from the training dataset) or fake (generated by the generator). - Uses a convolutional neural network (CNN) to extract features and make predictions. - Outputs a probability score indicating the likelihood that the input is real.
#Adversarial Training Process The training of a GAN is framed as a minimax game, where the generator and discriminator compete in a zero-sum game. The process can be summarized as follows:
- Initialization: - Both the generator and discriminator are initialized with random weights.
- Training Loop:
- Step 1: Train the Discriminator (D): - The discriminator is fed a batch of real data (from the training set) and a batch of fake data (generated by the generator). - It learns to classify real data as "1" and fake data as "0" by minimizing the binary cross-entropy loss.
- Step 2: Train the Generator (G): - The generator receives random noise as input and generates fake data. - The discriminator evaluates the fake data, and the generator aims to "fool" the discriminator by minimizing the loss (i.e., making the discriminator classify fakes as real). - The generator’s loss is derived from the discriminator’s output, encouraging it to produce more realistic samples.
- Alternating Optimization: - The discriminator and generator are trained alternately, with the discriminator improving its ability to detect fakes and the generator improving its ability to produce them. - Over time, the generator becomes proficient at creating high-quality synthetic data, while the discriminator becomes adept at identifying subtle differences between real and fake data.
#Mathematical Formulation The GAN training process can be mathematically represented as a minimax game with the following objective function: \[ \min_G \max_D V(D, G) = \mathbbE_x \sim p_data(x)[\log D(x)] + \mathbbE_z \sim p_z(z)[\log (1 - D(G(z)))] \] Where: - ( D(x) ) is the discriminator’s output for real data ( x ). - ( G(z) ) is the generator’s output for noise ( z ). - ( p_data(x) ) is the distribution of real data. - ( p_z(z) ) is the distribution of the noise input (typically Gaussian or uniform). The generator aims to minimize ( \log(1 - D(G(z))) ), while the discriminator aims to maximize ( \log D(x) + \log(1 - D(G(z))) ).
#Challenges in Training
- Mode Collapse: The generator produces limited varieties of outputs, failing to capture the full diversity of the real data distribution.
- Training Instability: The adversarial nature of GANs can lead to oscillations or divergence, where neither network improves.
- Vanishing Gradients: The discriminator may become too good too quickly, causing the generator’s gradients to vanish and halting learning.
- Evaluation Metrics: Measuring GAN performance is non-trivial, as traditional metrics like accuracy are not applicable. Common evaluation methods include Inception Score (IS) and Fréchet Inception Distance (FID).
#Important Facts
- Unsupervised Learning: GANs operate in an unsupervised manner, learning from unlabeled data to generate new samples.
- No Explicit Probability Density Estimation: Unlike traditional generative models (e.g., VAEs), GANs do not explicitly model the data distribution. Instead, they learn to sample from it implicitly.
- High-Quality Outputs: GANs are capable of generating high-resolution images, realistic audio, and coherent text, often surpassing other generative models in perceptual quality.
- Data Efficiency: GANs can generate large datasets from small training sets, making them useful in domains where data collection is expensive or impractical.
- Ethical Concerns: The ability to generate realistic fake data has raised ethical issues, particularly in the context of deepfakes, misinformation, and privacy violations.
- Hardware Requirements: Training GANs, especially high-resolution variants like StyleGAN, requires significant computational resources, often necessitating GPUs or TPUs.
- Applications in Drug Discovery: GANs are used to generate novel molecular structures for drug development, accelerating the discovery process.
- Artistic Applications: Artists and designers use GANs to create AI-generated art, music, and interactive experiences, pushing the boundaries of creativity.
#Timeline
- Foundational ideas
Core concepts and early methods shape What Is a GAN (generative Adversarial Network)?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does What Is a GAN (generative Adversarial Network)? cover?
Explains What Is a GAN (generative Adversarial Network), including the core definition, how it works, practical examples, and limitations.
Why is What Is a GAN (generative Adversarial Network)? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Generative AI decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as GAN, Generative, Adversarial before using the ideas in real projects.
#References
- What Is a GAN (generative Adversarial Network)? terminology and background research
- What Is a GAN (generative Adversarial Network)? use cases, implementation examples, and limitations
- Generative AI best practices, standards, and risk guidance
- GAN case studies, benchmarks, and current industry analysis




Comments
No comments yet. Start the discussion with a useful note.