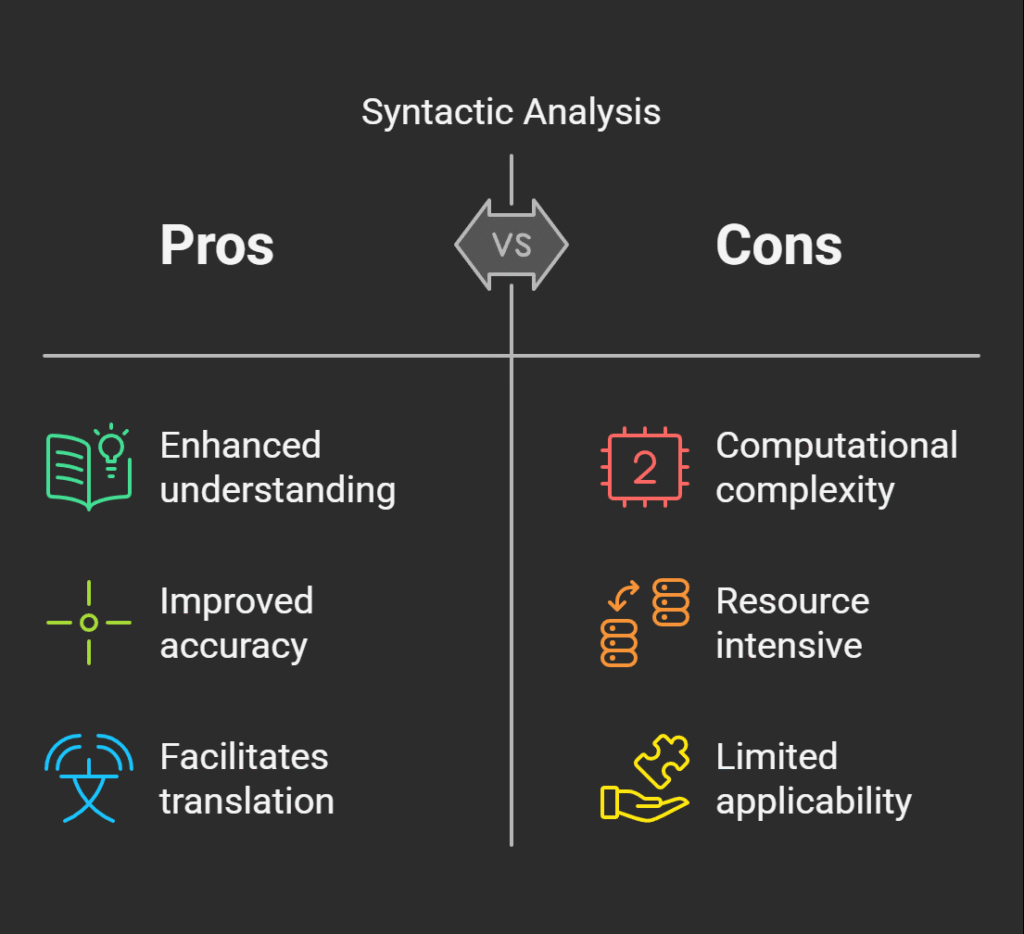
#Short Answer
Covers natural language processing: pros and cons, including core concepts, practical examples, benefits, limitations, and risks in Language AI.
#Infobox
#Overview
Natural Language Processing (NLP) is a multidisciplinary field that combines computational linguistics, computer science, and AI to enable machines to interact with human language in a meaningful way. Unlike traditional programming, which relies on structured data, NLP deals with unstructured text and speech, requiring advanced algorithms to extract patterns, semantics, and context. The primary objective of NLP is to develop systems that can perform tasks such as language translation, text classification, and conversational agents. These systems leverage techniques from machine learning (ML), deep learning, and statistical modeling to process and generate language with increasing accuracy. NLP has become integral to modern technology, powering virtual assistants like Siri and Alexa, search engines, and customer service automation.
#History / Background
#Early Foundations (1950s–1960s)
The origins of NLP trace back to the post-World War II era, when researchers began exploring the possibility of machines understanding human language. In 1950, Alan Turing proposed the "Turing Test" as a benchmark for machine intelligence, challenging systems to exhibit human-like conversational abilities. This laid the groundwork for early NLP research. In 1954, IBM and Georgetown University demonstrated the first machine translation system, translating Russian sentences into English. However, these early systems relied on rigid rule-based approaches, which struggled with the complexity and variability of natural language.
#Rule-Based Systems (1970s–1980s)
During this period, NLP research focused on developing rule-based systems that used handcrafted linguistic rules to parse and generate text. Projects like SHRDLU, an early natural language understanding program, demonstrated the potential of rule-based approaches in constrained environments. However, these systems were limited by their inability to handle ambiguity and context.
#Statistical NLP (1990s–2000s)
The advent of statistical methods revolutionized NLP by introducing probabilistic models to analyze language patterns. Researchers began using techniques such as Hidden Markov Models (HMMs) for speech recognition and part-of-speech tagging. The introduction of the Penn Treebank in 1993 provided a standardized dataset for training and evaluating NLP models, accelerating progress.
#Machine Learning and Deep Learning (2010s–Present)
The rise of machine learning, particularly deep learning, transformed NLP by enabling systems to learn language patterns directly from data. Techniques such as word embeddings (e.g., Word2Vec, GloVe) and neural networks (e.g., Recurrent Neural Networks, Transformers) significantly improved the accuracy of language models. Key milestones include the development of the Transformer architecture in 2017, which underpins modern models like BERT and GPT. These models leverage attention mechanisms to capture long-range dependencies in text, achieving state-of-the-art performance in tasks such as language understanding and generation.
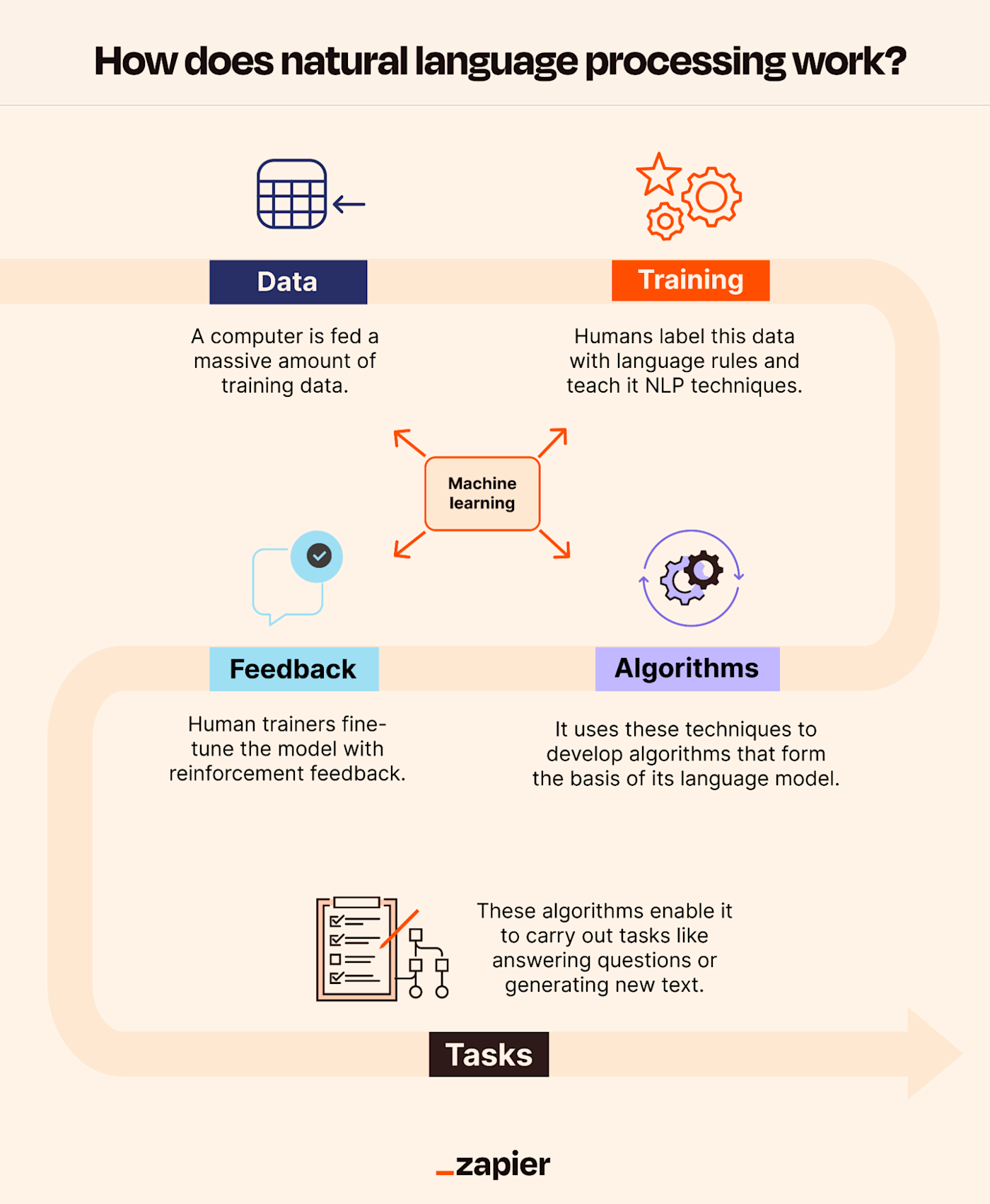
#How It Works
#Core Components of NLP
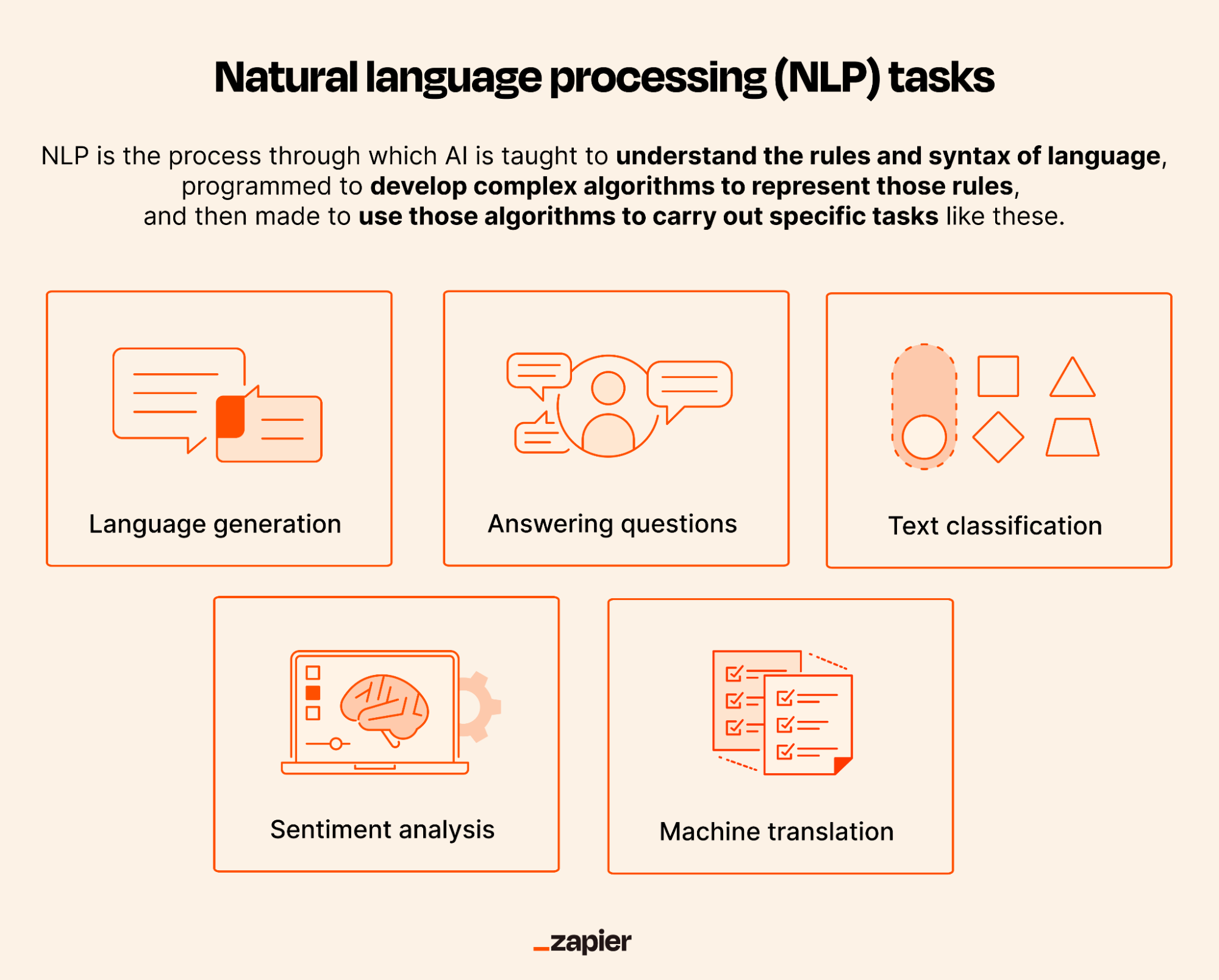
- Tokenization Tokenization is the process of breaking down text into smaller units, such as words or sentences, called tokens. This step is crucial for preparing text data for further processing. For example, the sentence "Natural Language Processing is fascinating" might be tokenized into ["Natural", "Language", "Processing", "is", "fascinating"].
- Part-of-Speech (POS) Tagging POS tagging assigns grammatical labels (e.g., noun, verb, adjective) to each token in a sentence. This helps in understanding the syntactic structure of the text. For instance, the word "processing" might be tagged as a noun or verb depending on the context.
- Named Entity Recognition (NER) NER identifies and classifies named entities in text, such as people, organizations, locations, and dates. For example, in the sentence "Apple Inc. was founded by Steve Jobs in 1976," NER would identify "Apple Inc." as an organization, "Steve Jobs" as a person, and "1976" as a date.
- Syntactic Parsing Syntactic parsing analyzes the grammatical structure of a sentence to determine relationships between words. This involves creating parse trees that represent the hierarchical structure of the sentence. For example, the sentence "The cat chased the mouse" would be parsed to show that "chased" is the root verb, with "cat" as the subject and "mouse" as the object.
- Semantic Analysis Semantic analysis focuses on understanding the meaning of text beyond syntax. This includes tasks such as word sense disambiguation (determining the correct meaning of a word in context) and semantic role labeling (identifying the roles of entities in a sentence).
- Sentiment Analysis Sentiment analysis determines the emotional tone of a piece of text, classifying it as positive, negative, or neutral. This is widely used in social media monitoring, customer feedback analysis, and market research.
- Machine Translation Machine translation involves converting text or speech from one language to another. Modern systems, such as those based on the Transformer architecture, use deep learning to produce more accurate and contextually appropriate translations.
- Text Generation Text generation involves creating coherent and contextually relevant text based on a given prompt. Applications include chatbots, content creation, and automated storytelling.
#Key Techniques
and Models
- Word Embeddings: Represent words as dense vectors in a continuous space, capturing semantic relationships. Examples include Word2Vec, GloVe, and FastText.
- Recurrent Neural Networks (RNNs): Suitable for sequential data, RNNs process text word by word, maintaining a hidden state to capture context. Variants like Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRUs) address the vanishing gradient problem.
- Transformers: Introduced in the paper "Attention Is All You Need" (2017), Transformers use self-attention mechanisms to process entire sequences simultaneously, enabling parallelization and improved performance.
- Pre-trained Language Models: Models like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer) are pre-trained on large corpora and fine-tuned for specific tasks, achieving high accuracy with minimal task-specific data.
#Important Facts
- NLP in Everyday Life: NLP powers applications such as voice assistants (e.g., Siri, Alexa), email spam filters, and language translation services (e.g., Google Translate).
- Multilingual Capabilities: Modern NLP systems support over 100 languages, enabling cross-lingual communication and localization.
- Ethical Concerns: NLP systems can perpetuate biases present in training data, leading to unfair outcomes in areas such as hiring, lending, and law enforcement.
- Computational Resources: Training large language models requires significant computational power, often necessitating the use of GPUs or TPUs and cloud-based infrastructure.
- Evaluation Metrics: Common metrics for assessing NLP models include accuracy, precision, recall, F1-score, and BLEU score (for machine translation).
- Open-Source Tools: Popular NLP libraries include NLTK, spaCy, Hugging Face Transformers, and Stanford CoreNLP, which provide pre-built models and tools for various NLP tasks.
#Timeline
- Foundational ideas
Core concepts and early methods shape Natural Language Processing: Pros and Cons.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Natural Language Processing: Pros and Cons cover?
Covers natural language processing: pros and cons, including core concepts, practical examples, benefits, limitations, and risks in Language AI.
Why is Natural Language Processing: Pros and Cons important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Language AI decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Natural, Language, Processing before using the ideas in real projects.
#References
- Natural Language Processing: Pros and Cons terminology and background research
- Natural Language Processing: Pros and Cons use cases, implementation examples, and limitations
- Language AI best practices, standards, and risk guidance
- Natural case studies, benchmarks, and current industry analysis
Comments
No comments yet. Start the discussion with a useful note.