#Short Answer
Covers meaning of natural language processing, including core concepts, practical examples, benefits, limitations, and risks in Language AI.
#Infobox
#Overview
Natural Language Processing (NLP) bridges the gap between human communication and computer understanding. Unlike traditional programming languages, which follow strict syntax rules, natural languages—such as English, Spanish, or Mandarin—are rich in ambiguity, context, and cultural nuances. NLP seeks to equip machines with the ability to process and derive meaning from unstructured text or speech data, enabling a wide range of applications that enhance human-computer interaction. At its core, NLP combines techniques from linguistics, computer science, and statistical modeling to analyze and generate human language. It encompasses both rule-based systems (e.g., parsing grammars) and machine learning models (e.g., neural networks) to handle tasks such as text classification, named entity recognition, and machine translation. The field has evolved significantly with advancements in deep learning, particularly transformer models like BERT and GPT, which have revolutionized how machines understand context and generate coherent text. Today, NLP is integral to modern AI systems, powering everything from virtual assistants like Siri and Alexa to automated customer service platforms.
#History / Background
#Early Foundations (Pre-1950s)
The conceptual roots of NLP trace back to the 17th century, when philosophers like René Descartes and Gottfried Wilhelm Leibniz speculated about the mechanization of thought and language. However, the formal study of NLP began in the mid-20th century, influenced by developments in computational theory and linguistics.
#The Turing Test and Early AI (1950s)
In 1950, Alan Turing proposed the Turing Test in his seminal paper "Computing Machinery and Intelligence", which posed the question: Can a machine exhibit intelligent behavior indistinguishable from that of a human? This laid the groundwork for AI and, by extension, NLP. The same decade saw the first attempts at machine translation, with projects like the Georgetown-IBM experiment (1954), which translated 60 Russian sentences into English using a rule-based system.
#The Chomsky Revolution (1957–1960s)
The publication of Noam Chomsky’s "Syntactic Structures" (1957) revolutionized linguistics by introducing generative grammar, a formal system for describing language structure. Chomsky’s theories influenced early NLP approaches, which relied heavily on rule-based syntactic parsing. During this period, projects like SHRDLU (1968–1970) demonstrated how a computer could understand and manipulate language in a constrained domain (e.g., a virtual block world).
#The AI Winter and Statistical NLP (1970s–1980s)
The 1970s and 1980s saw a decline in AI research funding, known as the AI Winter, due to unmet expectations. However, NLP continued to progress with the rise of statistical methods. Researchers like Frederick Jelinek at IBM pioneered statistical language modeling, which used probabilistic techniques to improve speech recognition and machine translation. The Hidden Markov Model (HMM) became a cornerstone for early NLP tasks, particularly in speech processing.
#The Rise of Machine Learning (1990s–2000s)
The 1990s marked a shift toward data-driven approaches, fueled by the growth of the internet and digital text corpora. The Penn Treebank (1993), a corpus of annotated English sentences, became a benchmark for training and evaluating NLP models. During this era, support vector machines (SVMs) and maximum entropy models gained popularity for tasks like part-of-speech tagging and named entity recognition. The 2000s saw the emergence of supervised learning and feature engineering, with tools like NLTK (Natural Language Toolkit) democratizing NLP research. The WordNet lexical database (1998) also became a vital resource for semantic analysis.
#The Deep Learning Revolution (2010s–Present)
The 2010s brought a paradigm shift with the advent of deep learning, particularly recurrent neural networks (RNNs) and convolutional neural networks (CNNs). Models like Word2Vec (2013) introduced distributed representations of words, capturing semantic relationships (e.g., "king" - "man" + "woman" ≈ "queen"). A major breakthrough came in 2017 with the introduction of transformer models, notably Vaswani et al.’s "Attention Is All You Need" paper, which proposed the Transformer architecture. This architecture underpins modern models like BERT (Bidirectional Encoder Representations from Transformers, 2018) and GPT (Generative Pre-trained Transformer, 2018), which have set new benchmarks in NLP tasks such as question answering, text summarization, and machine translation. Today, NLP is a multibillion-dollar industry, with applications spanning healthcare (clinical NLP), finance (sentiment analysis), education (automated grading), and social media (content moderation).
#How It Works
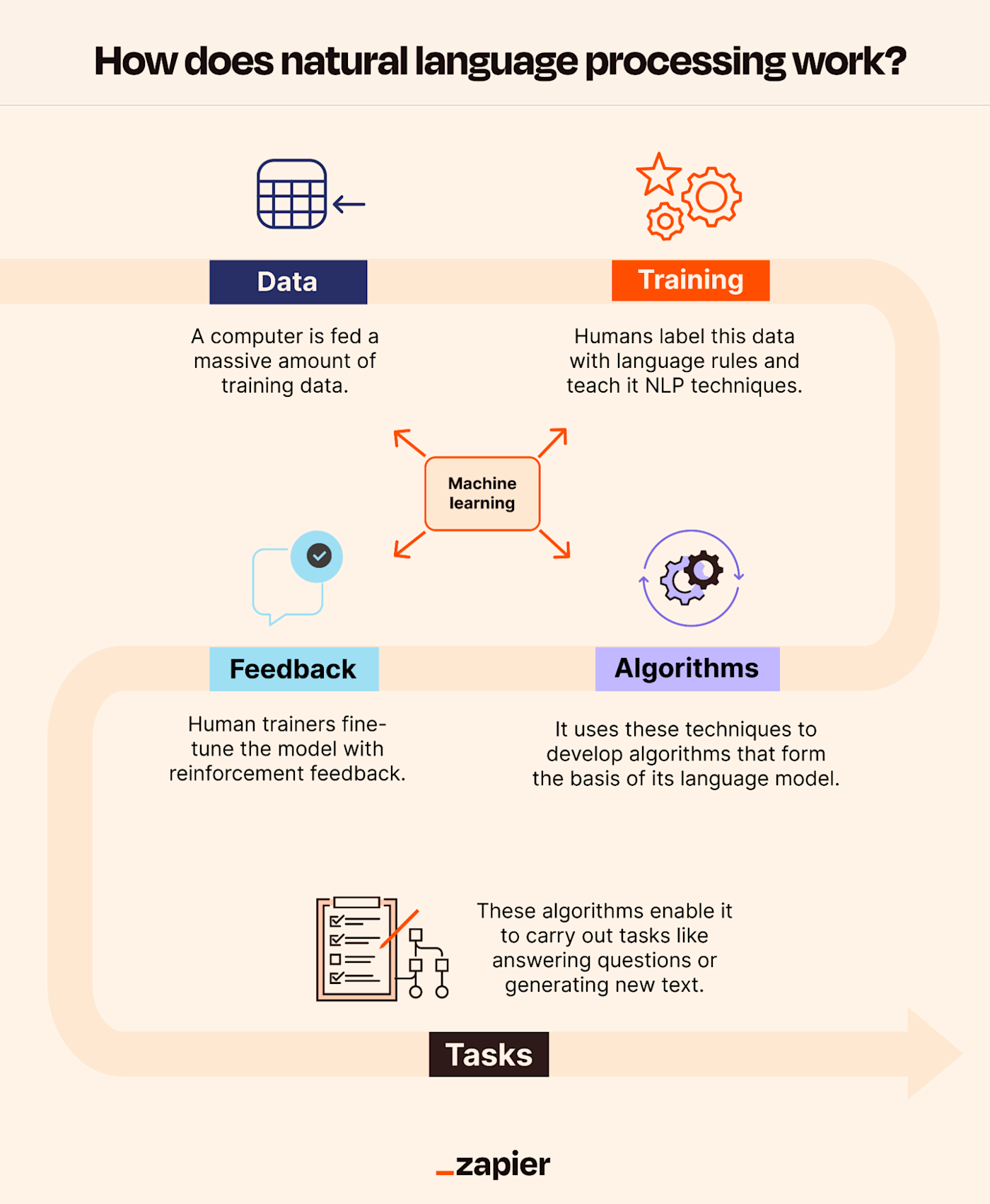
NLP systems process human language through a pipeline of steps, each designed to handle specific challenges in language understanding and generation. The process can be broadly divided into five key stages:
#
- Text Preprocessing Before analysis, raw text data must be cleaned and standardized to improve model performance. Common preprocessing steps include:
- Tokenization: Splitting text into individual words, phrases, or sentences (e.g., "Natural Language Processing" → ["Natural", "Language", "Processing"]).
- Normalization: Converting text to a consistent format (e.g., lowercase conversion, removing punctuation, expanding contractions like "don’t" → "do not").
- Stopword Removal: Filtering out common words (e.g., "the", "is", "and") that add little semantic value.
- Stemming/Lemmatization: Reducing words to their base or root form (e.g., "running" → "run", "better" → "good").
- Part-of-Speech (POS) Tagging: Labeling words with grammatical categories (e.g., noun, verb, adjective).
#
- Syntactic Analysis This stage focuses on the grammatical structure of sentences. Techniques include:
- Parsing: Building a parse tree to represent the syntactic structure of a sentence (e.g., identifying subject-verb-object relationships).
- Dependency Parsing: Mapping grammatical dependencies between words (e.g., "The cat sat on the mat" → "sat" depends on "cat").
- Constituency Parsing: Grouping words into hierarchical phrases (e.g., noun phrases, verb phrases).
#
- Semantic Analysis Semantic analysis aims to extract meaning from text. Key methods include:
- Word Sense Disambiguation: Determining the correct meaning of a word in context (e.g., "bank" as a financial institution vs. a riverbank).
- Named Entity Recognition (NER): Identifying and classifying entities (e.g., people, organizations, locations) in text.
- Coreference Resolution: Linking pronouns or noun phrases to their referents (e.g., "She" → "Mary").
- Sentiment Analysis: Classifying text as positive, negative, or neutral (e.g., analyzing customer reviews).
- Topic Modeling: Identifying abstract topics in a collection of documents (e.g., using Latent Dirichlet Allocation (LDA)).
#
- Discourse and Pragmatic Analysis This stage examines contextual and situational meaning, going beyond individual sentences:
- Discourse Analysis: Understanding how sentences relate to each other in a text (e.g., coherence, cohesion).
- Pragmatic Analysis: Interpreting language in context, including implicature (implied meaning) and speech acts (e.g., "Can you pass the salt?" as a request rather than a question).
- Dialogue Systems: Modeling conversational flow in chatbots or virtual assistants.
#
- Language Generation The final stage involves generating human-like text from structured data. Approaches include:
- Template-Based Generation: Filling predefined templates with extracted data (e.g., weather reports).
- Neural Language Models: Using deep learning models (e.g., GPT-3, T5) to generate coherent and contextually appropriate text.
- Summarization: Condensing long documents into concise summaries (e.g., abstractive or extractive summarization).
- Machine Translation: Translating text from one language to another (e.g., Google Translate, DeepL).
#Key NLP Techniques and Models
| Technique/Model | Description | Use Cases | |---------------------------|---------------------------------------------------------------------------------|----------------------------------------| | Bag-of-Words (BoW) | Represents text as a multiset of words, ignoring grammar and word order. | Text classification, spam detection | | TF-IDF | Weighs words by their importance in a document relative to a corpus. | Information retrieval, document ranking | | Word Embeddings | Maps words to dense vector representations (e.g., Word2Vec, GloVe, FastText). | Semantic similarity, NER | | Recurrent Neural Networks (RNNs) | Processes sequences sequentially, capturing temporal dependencies. | Time-series text, language modeling | | Long Short-Term Memory (LSTM) | A type of RNN that mitigates the vanishing gradient problem. | Machine translation, speech recognition | | Transformer Models | Uses self-attention mechanisms to process entire sequences in parallel. | BERT, GPT, T5 | | Attention Mechanisms | Allows models to focus on relevant parts of the input. | Question answering, summarization |
#Important Facts
- NLP is Everywhere: From spell checkers in word processors to real-time translation in apps like Google Translate, NLP is embedded in daily digital interactions.
- Multilingual NLP: Modern NLP systems support over 100 languages, though performance varies significantly between high-resource (e.g., English, Mandarin) and low-resource languages (e.g., Swahili, Quechua).
- Bias in NLP: Models can inherit biases from training data, leading to discriminatory outputs (e.g., gender or racial biases in sentiment analysis).
- Explainability: Many NLP models, especially deep learning-based ones, are "black boxes"—their decisions are hard to interpret, posing challenges for applications in healthcare or law.
- Ethical Concerns: NLP raises ethical issues such as privacy violations (e.g., analyzing private communications), misinformation spread, and deepfake text generation.
- Energy Consumption: Training large NLP models (e.g., GPT-3) requires significant computational resources, contributing to environmental concerns.
- Human-in-the-Loop: Many NLP systems incorporate human feedback to improve accuracy, especially in domains like medical diagnosis or legal document analysis.
- Cross-Domain Adaptation: NLP models trained on one domain (e.g., news articles) may perform poorly on another (e.g., medical texts), requiring domain adaptation techniques.
#Timeline
- Foundational ideas
Core concepts and early methods shape Meaning of Natural Language Processing.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Meaning of Natural Language Processing cover?
Covers meaning of natural language processing, including core concepts, practical examples, benefits, limitations, and risks in Language AI.
Why is Meaning of Natural Language Processing important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Language AI decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Meaning, Natural, Language before using the ideas in real projects.
#References
- Meaning of Natural Language Processing terminology and background research
- Meaning of Natural Language Processing use cases, implementation examples, and limitations
- Language AI best practices, standards, and risk guidance
- Meaning case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.