
#Short Answer
Explains how to fine-tune a language model, including the main process, tools, examples, risks, and practical implementation steps.
#Infobox
#Overview
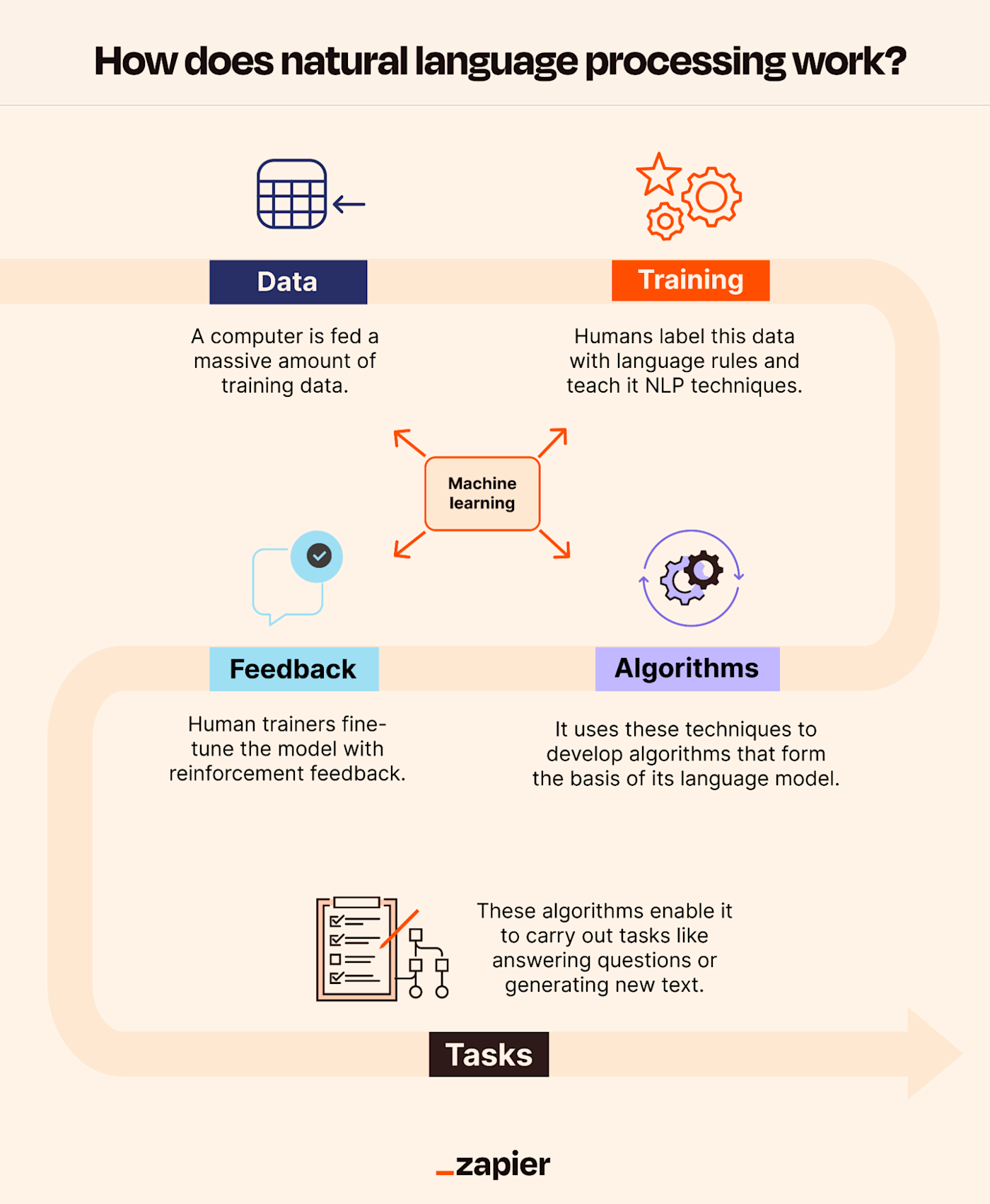
Fine-tuning a language model is a critical technique in natural language processing (NLP) that bridges the gap between general-purpose pre-trained models and task-specific applications. Unlike training a model from scratch—which requires massive computational resources and extensive datasets—fine-tuning starts with a model already trained on vast amounts of text data. This pre-trained model is then further trained on a smaller, task-specific dataset, allowing it to specialize in areas such as sentiment analysis, machine translation, or legal document processing. The process leverages transfer learning, where the model retains its foundational knowledge while adapting to new contexts. Fine-tuning is particularly valuable in industries where domain-specific language patterns are essential, such as healthcare, finance, or legal services. By refining the model’s parameters, fine-tuning improves its accuracy and relevance for targeted applications without the need for retraining from zero.
#History / Background
The concept of fine-tuning in machine learning emerged alongside the development of deep learning and large-scale language models. Early NLP models relied on handcrafted features and rule-based systems, which were limited in scalability and adaptability. The introduction of pre-trained models like Word2Vec (2013) and GloVe (2014) marked a shift toward leveraging unsupervised learning for language representation. The breakthrough came with the Transformer architecture (Vaswani et al., 2017), which enabled the creation of large-scale pre-trained models such as BERT (Devlin et al., 2018) and GPT (Radford et al., 2018). These models demonstrated the power of self-supervised learning, where they were pre-trained on massive corpora (e.g., Wikipedia, Common Crawl) to learn general language patterns. Fine-tuning became the natural next step, allowing researchers and practitioners to adapt these models to specific tasks with minimal additional data. Key milestones in the evolution of fine-tuning include:
- 2018: Introduction of BERT and its fine-tuning framework for tasks like text classification and named entity recognition.
- 2019: Development of ULMFiT (Universal Language Model Fine-tuning), which popularized the idea of progressive fine-tuning across multiple tasks.
- 2020: Release of T5 (Text-to-Text Transfer Transformer), which framed all NLP tasks as text-to-text problems, simplifying fine-tuning workflows.
- 2021–2023: Advancements in parameter-efficient fine-tuning (PEFT) techniques like LoRA (Low-Rank Adaptation) and QLoRA, which reduced computational costs while maintaining performance. Today, fine-tuning is a cornerstone of modern NLP, enabling applications in chatbots, virtual assistants, and domain-specific AI systems.
#How It Works
Fine-tuning a language model involves several key steps, each designed to adapt the pre-trained model to a specific task while preserving its general knowledge. The process can be broken down into the following stages:
#
- Pre-trained Model Selection - Choose a pre-trained model based on the task requirements (e.g., BERT for classification, GPT for generation). - Consider factors like model size, architecture, and pre-training data.
#
- Task-Specific Data Preparation - Collect and preprocess a dataset relevant to the target task (e.g., customer reviews for sentiment analysis). - Clean the data (remove noise, handle missing values) and format it for the model (e.g., tokenization, labeling).
#
- Model Adaptation
- Full Fine-Tuning: Update all model parameters using the task-specific dataset. This is computationally expensive but often yields the best performance.
- Parameter-Efficient Fine-Tuning (PEFT): Modify only a subset of parameters (e.g., using LoRA or Adapters) to reduce computational costs while maintaining accuracy.
- Prompt-Based Fine-Tuning: Frame the task as a prompt (e.g., "Translate this sentence to French") and fine-tune the model to follow instructions.
#
- Training Process
- Learning Rate Adjustment: Use a lower learning rate than pre-training to avoid catastrophic forgetting (loss of general knowledge).
- Batch Size and Epochs: Optimize these hyperparameters to balance training time and performance.
- Regularization: Apply techniques like dropout or early stopping to prevent overfitting.
#
- Evaluation and Deployment - Test the fine-tuned model on a held-out validation set to assess performance (e.g., accuracy, F1 score). - Deploy the model in production, either as an API or embedded in an application.
#Example Workflow (Sentiment Analysis) 1. Start with a pre-trained BERT model. 2. Prepare a dataset of labeled reviews (e.g., positive/negative). 3. Fine-tune BERT on this dataset using a learning rate of 2e-5. 4. Evaluate the model on a test set and deploy it for real-time sentiment analysis.
#Important Facts
- Transfer Learning Efficiency: Fine-tuning leverages the knowledge embedded in pre-trained models, reducing the need for large labeled datasets.
- Domain Adaptation: Models fine-tuned on domain-specific data (e.g., medical texts) outperform general-purpose models in specialized tasks.
- Computational Cost: Full fine-tuning requires significant GPU/TPU resources, while PEFT methods like LoRA reduce costs by 10–100x.
- Catastrophic Forgetting: Overfitting to the task-specific data can degrade the model’s general language understanding. Mitigation strategies include using lower learning rates or replaying pre-training data.
- Few-Shot Learning: Fine-tuning can enable models to perform well with minimal task-specific data (e.g., 10–100 examples).
- Ethical Considerations: Fine-tuned models may inherit biases from the pre-training data or task-specific dataset, requiring careful evaluation and mitigation.
#Timeline
- Foundational ideas
Core concepts and early methods shape How to Fine-tune a Language Model.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does How to Fine-tune a Language Model cover?
Explains how to fine-tune a language model, including the main process, tools, examples, risks, and practical implementation steps.
Why is How to Fine-tune a Language Model important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Language AI decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Fine, Tune, Language before using the ideas in real projects.
#References
- How to Fine-tune a Language Model terminology and background research
- How to Fine-tune a Language Model use cases, implementation examples, and limitations
- Language AI best practices, standards, and risk guidance
- Fine case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.