#Short Answer
Explains how does deep learning work?, including the main process, tools, examples, risks, and practical implementation steps.
#Infobox
#History / Background
Early Foundations (1940s–1980s) The conceptual roots of deep learning trace back to the 1940s with the introduction of the first artificial neuron models, such as the perceptron by Frank Rosenblatt in 1958. However, early neural networks were limited by computational constraints and lacked efficient training methods. The 1980s saw the emergence of backpropagation, an algorithm that enabled neural networks to learn from errors by adjusting weights iteratively. This period also introduced the concept of multi-layer perceptrons (MLPs), though training deep networks remained challenging due to the vanishing gradient problem.
The "AI Winter" and Revival (1990s–2000s) During the 1990s, interest in neural networks waned due to limited success and the dominance of other AI approaches like support vector machines (SVMs). This era, known as the "AI winter," stifled progress until the mid-2000s. A turning point came with the work of Geoffrey Hinton, Simon Osindero, and Yee-Whye Teh, who demonstrated that deep belief networks (DBNs) could be trained effectively using a greedy layer-wise approach. This breakthrough reignited interest in deep learning and laid the groundwork for modern architectures.
The Deep Learning Revolution (2010s–Present) The 2010s marked the golden age of deep learning, driven by three pivotal developments:
- Big Data: The proliferation of digital data, particularly in images, text, and speech, provided the raw material for training large-scale models.
- Computational Power: Graphics processing units (GPUs) and later tensor processing units (TPUs) accelerated training times, making it feasible to train deep networks.
- Algorithmic Innovations: Advances such as rectified linear units (ReLUs), dropout regularization, and batch normalization improved model performance and stability. Key milestones include:
- 2012: AlexNet, a convolutional neural network (CNN) designed by Alex Krizhevsky, won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), achieving a top-5 error rate of 15.3%, far surpassing traditional methods.
- 2014: The introduction of sequence-to-sequence models by Google improved machine translation.
- 2016: DeepMind’s AlphaGo defeated a world champion Go player, demonstrating the potential of deep reinforcement learning.
- 2020s: The rise of transformer models, such as BERT and GPT-3, revolutionized NLP, enabling systems to generate human-like text and understand context with unprecedented accuracy. Today, deep learning underpins many cutting-edge technologies, from self-driving cars to personalized medicine, and continues to evolve with innovations like generative adversarial networks (GANs) and neural architecture search (NAS).
#How It Works
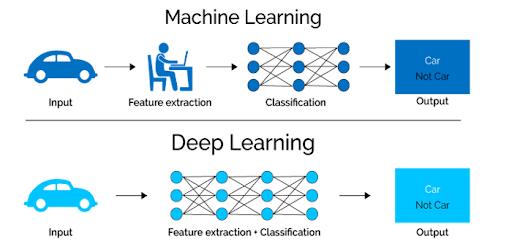
Neural Networks: The Building Blocks Deep learning is built on artificial neural networks (ANNs), which are inspired by the biological neural networks in the human brain. An ANN consists of:
- Input Layer: Receives raw data (e.g., pixels in an image, words in a sentence).
- Hidden Layers: Intermediate layers that transform the input data through weighted connections and activation functions. The depth of these layers defines the "deep" in deep learning.
- Output Layer: Produces the final prediction or classification (e.g., identifying an object in an image, translating a sentence). Each neuron in a layer is connected to neurons in the next layer, with the strength of these connections represented by weights. During training, these weights are adjusted to minimize the difference between the predicted output and the actual output, a process known as learning.
Key Components
- Activation Functions: - Introduce nonlinearity into the model, enabling it to learn complex patterns. - Common functions include ReLU (Rectified Linear Unit), sigmoid, and tanh. - Example: ReLU is defined as ( f(x) = \max(0, x) ), which helps mitigate the vanishing gradient problem.
- Loss Functions: - Measure the difference between predicted and actual outputs. - Common loss functions include mean squared error (MSE) for regression tasks and cross-entropy loss for classification tasks.
- Optimization Algorithms: - Adjust the weights of the network to minimize the loss function. - Popular algorithms include stochastic gradient descent (SGD), Adam, and RMSprop.
- Backpropagation: - A method for calculating the gradient of the loss function with respect to each weight in the network. - Uses the chain rule from calculus to propagate errors backward through the network, enabling efficient weight updates.
Types of Deep Learning Models
- Feedforward Neural Networks (FNNs): - The simplest form of ANNs, where data flows in one direction (input → hidden layers → output). - Used for tasks like classification and regression.
- Convolutional Neural Networks (CNNs): - Specialized for processing grid-like data, such as images. - Use convolutional layers to apply filters that detect local patterns (e.g., edges, textures). - Include pooling layers to reduce spatial dimensions and fully connected layers for classification. - Example: CNNs power facial recognition systems and medical image analysis.
- Recurrent Neural Networks (RNNs): - Designed for sequential data, such as time series or text. - Feature loops that allow information to persist, enabling the model to "remember" past inputs. - Variants include Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs), which address the vanishing gradient problem in traditional RNNs. - Example: RNNs are used in speech recognition and language modeling.
- Transformer Models: - Introduced in the paper "Attention Is All You Need" (2017), transformers rely on self-attention mechanisms to weigh the importance of different parts of the input. - Enable parallel processing of sequences, making them highly efficient for large-scale tasks. - Example: Models like BERT and GPT-3 use transformers for NLP tasks, including text generation and question answering.
- Generative Models: - Designed to generate new data similar to the training data. - Include Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs). - Example: GANs can create realistic images, while VAEs are used for data compression and anomaly detection.
- Reinforcement Learning (RL): - Combines deep learning with reinforcement learning to enable agents to learn optimal actions through trial and error. - Uses deep neural networks to approximate value functions or policies. - Example: Deep Q-Networks (DQNs) have been used to master complex games like Atari and Go.
Training Process
- Data Preparation: - Raw data is preprocessed (e.g., normalized, augmented) to improve model performance. - For supervised learning, data is labeled; for unsupervised learning, it is unlabeled.
- Model Initialization: - Weights are initialized randomly or using techniques like Xavier or He initialization to avoid vanishing or exploding gradients.
- Forward Pass: - Input data is passed through the network, and predictions are generated.
- Loss Calculation: - The loss function quantifies the difference between predictions and actual labels.
- Backward Pass (Backpropagation): - Gradients are computed using the chain rule, and weights are updated using an optimization algorithm (e.g., Adam).
- Iteration: - The process repeats for multiple epochs (iterations over the entire dataset) until the model converges (i.e., loss stabilizes).
- Evaluation: - The trained model is tested on unseen data to assess its generalization performance using metrics like accuracy, precision, recall, or F1-score.
#Important Facts
- Hierarchical Feature Learning: Deep learning models learn features in a hierarchical manner, with lower layers capturing simple features (e.g., edges in images) and higher layers capturing complex abstractions (e.g., object parts or entire objects).
- Transfer Learning: Pre-trained models (e.g., ResNet, BERT) can be fine-tuned for new tasks, reducing the need for large labeled datasets.
- Computational Intensity: Training deep learning models requires significant computational resources, often necessitating the use of GPUs or cloud-based solutions.
- Black Box Nature: While deep learning models achieve high accuracy, their internal workings are often opaque, making interpretability a challenge. Techniques like SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations) are used to explain model decisions.
- Data Hunger: Deep learning models typically require large datasets to generalize well. Techniques like data augmentation and synthetic data generation are used to address this.
- Ethical Concerns: Issues such as bias in training data, privacy violations, and the potential for misuse (e.g., deepfakes) are critical considerations in the deployment of deep learning systems.
#Timeline
- Foundational ideas
Core concepts and early methods shape How Does Deep Learning Work?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does How Does Deep Learning Work? cover?
Explains how does deep learning work?, including the main process, tools, examples, risks, and practical implementation steps.
Why is How Does Deep Learning Work? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Does, Deep, Learning before using the ideas in real projects.
#References
- How Does Deep Learning Work? terminology and background research
- How Does Deep Learning Work? use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Does case studies, benchmarks, and current industry analysis



Comments
No comments yet. Start the discussion with a useful note.