#Short Answer
Explains What Is a Random Forest, including the core definition, how it works, practical examples, and limitations.
#Infobox
#Overview
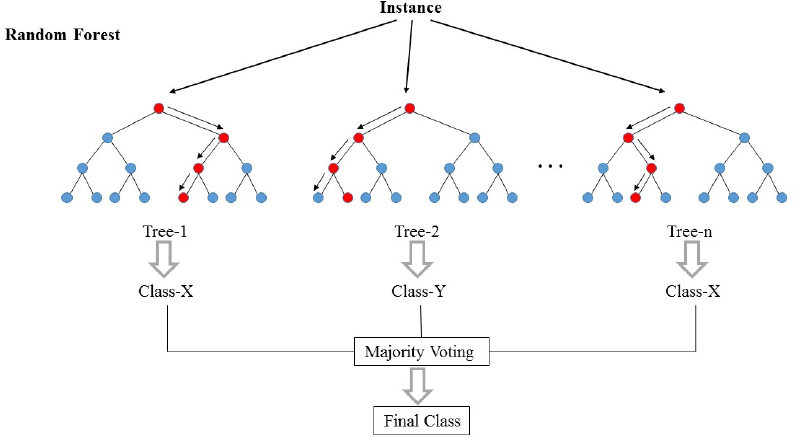
A Random Forest is an ensemble learning technique that combines the predictions of multiple base estimators (typically decision trees) to improve generalization and reduce variance. Unlike single decision trees, which can suffer from high variance and overfitting, Random Forests leverage bagging (Bootstrap Aggregating) and feature randomness to create a robust model. The algorithm is widely used in data science, finance, healthcare, and bioinformatics due to its ability to handle high-dimensional data, missing values, and noisy datasets. Its non-parametric nature makes it adaptable to various problem domains, including image classification, fraud detection, and predictive maintenance.
#History / Background
#Origins of Ensemble Methods The concept of ensemble learning dates back to the 1990s, with early work on bagging (Breiman, 1996) and boosting (Freund & Schapire, 1997). These methods aimed to improve model performance by combining multiple weak learners.
#Development of Random Forests The Random Forest algorithm was formally introduced in 2001 by Leo Breiman and Adele Cutler, building upon earlier ensemble techniques. Breiman’s work extended the idea of bagging by incorporating random feature selection at each split in the decision trees, which further reduced correlation between trees and improved generalization.
#Evolution and Adoption
- 2000s: Random Forests gained popularity in machine learning competitions (e.g., Kaggle) due to their high accuracy and ease of use.
- 2010s: The algorithm became a standard tool in scikit-learn, R (randomForest package), and other ML libraries.
- 2020s: Advances in computational power and parallel processing (e.g., GPU acceleration) have made Random Forests scalable for big data applications.
#How It Works
#Core Principles
- Bootstrap Aggregating (Bagging) - The training dataset is randomly sampled with replacement to create multiple subsets (bootstrap samples). - Each subset is used to train a decision tree, resulting in a forest of trees.
- Feature Randomness - At each node of a decision tree, a random subset of features is considered for splitting, rather than all features. - This introduces diversity among trees, reducing correlation and improving robustness.
- Aggregation of Predictions - For classification, the final prediction is the majority vote of all trees. - For regression, the final prediction is the average of all tree outputs.
#Step-by-Step Process
- Input Data: A dataset with
nsamples andmfeatures. - Bootstrap Sampling: Generate
kbootstrap samples (typicallyk = n_estimators). - Tree Construction: - For each bootstrap sample, grow a decision tree. - At each split, randomly select
sqrt(m)features (for classification) orm/3features (for regression). - Split the node using the best feature (e.g., Gini impurity or mean squared error). - Prediction: - For a new input, pass it through all trees. - Aggregate predictions (vote or average) to produce the final output.
#Mathematical Formulation
- Bootstrap Sample: ( D_i ) is a sample drawn with replacement from the original dataset ( D ).
- Feature Subset: At each node, a random subset ( F \subset \1, 2, ..., m\ ) is selected.
- Split Criterion:
- Classification: Minimize Gini impurity or entropy.
- Regression: Minimize mean squared error (MSE).
#Important Facts
#Advantages ✅ High Accuracy: Often outperforms single decision trees and many other algorithms. ✅ Robustness to Overfitting: Reduces variance by averaging multiple trees. ✅ Handles Large Datasets: Efficient with high-dimensional data. ✅ Feature Importance: Provides insights into which features contribute most to predictions. ✅ No Need for Scaling: Unlike SVM or neural networks, Random Forests do not require feature scaling. ✅ Works with Missing Data: Can handle missing values without imputation.
#Disadvantages ❌ Computationally Expensive: Training multiple trees requires significant resources. ❌ Less Interpretable: Harder to explain than single decision trees. ❌ Bias in High-Dimensional Data: If many features are irrelevant, performance may degrade. ❌ Memory-Intensive: Storing all trees can be resource-heavy.
#Common Use Cases
- Finance: Credit scoring, fraud detection.
- Healthcare: Disease prediction, patient risk assessment.
- Marketing: Customer segmentation, churn prediction.
- Computer Vision: Image classification, object detection.
- Natural Language Processing (NLP): Text classification, sentiment analysis.
#Timeline
- Foundational ideas
Core concepts and early methods shape What Is a Random Forest?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does What Is a Random Forest? cover?
Explains What Is a Random Forest, including the core definition, how it works, practical examples, and limitations.
Why is What Is a Random Forest? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Artificial Intelligence decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Random, Forest, AI before using the ideas in real projects.
#References
- What Is a Random Forest? terminology and background research
- What Is a Random Forest? use cases, implementation examples, and limitations
- Artificial Intelligence best practices, standards, and risk guidance
- Random case studies, benchmarks, and current industry analysis




Comments
No comments yet. Start the discussion with a useful note.