#Short Answer
Explains What Is a LSTM (long Short-term Memory), including the core definition, how it works, practical examples, and limitations.
#Infobox
#Overview
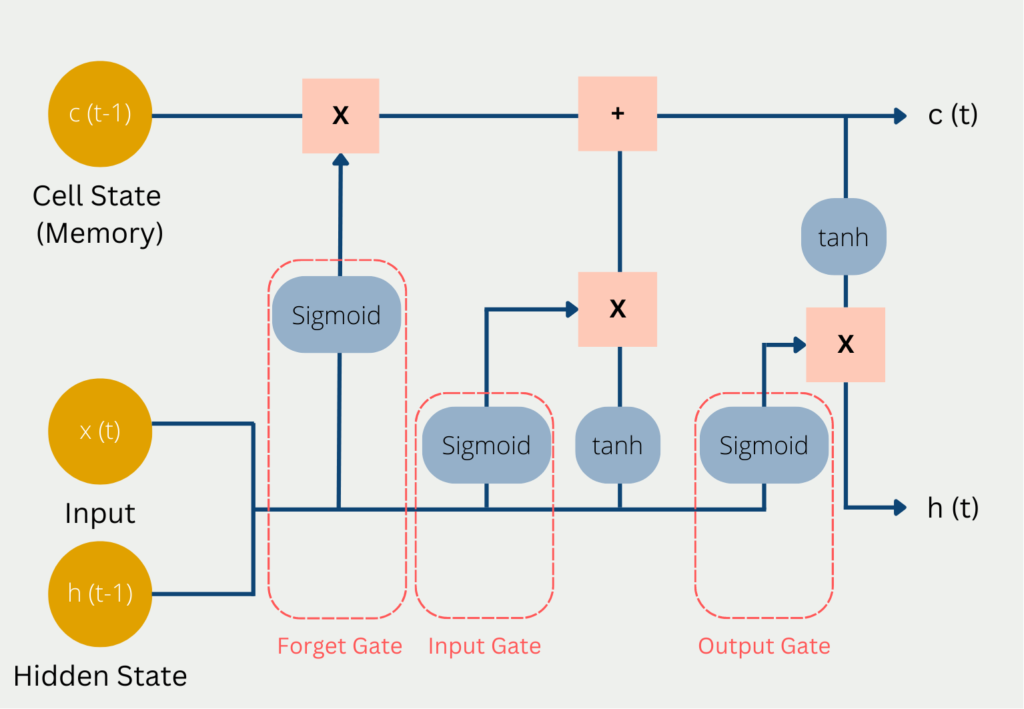
Long Short-Term Memory (LSTM) networks are a specialized form of recurrent neural networks (RNNs) engineered to address the limitations of traditional RNNs, particularly the vanishing gradient problem. In standard RNNs, gradients computed during backpropagation diminish exponentially over time, making it difficult to learn dependencies across long sequences. LSTMs mitigate this issue by introducing a memory cell and gating mechanisms that selectively retain or discard information, enabling the network to capture patterns spanning hundreds or even thousands of time steps. The architecture of an LSTM unit consists of three primary components:
- Forget Gate: Decides which information from the previous cell state should be discarded.
- Input Gate: Determines which new information should be stored in the cell state.
- Output Gate: Controls how much of the cell state is output to the next hidden state. This gating system allows LSTMs to maintain a constant error flow through the cell state, ensuring that long-term dependencies are preserved. As a result, LSTMs have become a cornerstone in modern deep learning applications, particularly in domains where sequential data plays a critical role.
#History / Background
The development of LSTMs traces back to the mid-1990s, when researchers sought to overcome the inherent limitations of traditional RNNs. The foundational work was conducted by Sepp Hochreiter and Jürgen Schmidhuber, who introduced the LSTM architecture in their 1997 paper, "Long Short-Term Memory." Their research highlighted the vanishing gradient problem in RNNs and proposed a solution using constant error carousels (CECs) within the memory cells.
#Early Developments
- 1997: Hochreiter and Schmidhuber publish the original LSTM paper, demonstrating its superiority over standard RNNs in learning long-term dependencies.
- 1999: The first practical applications of LSTMs emerged, including handwriting recognition and speech synthesis.
- 2000s: LSTMs gained traction in the machine learning community, with improvements in training efficiency and scalability.
#Modern Advancements
- 2010s: LSTMs became a standard tool in deep learning, particularly in NLP tasks such as machine translation (e.g., Google’s Neural Machine Translation) and speech recognition (e.g., Apple’s Siri).
- 2014: The introduction of Bidirectional LSTMs (BiLSTMs) allowed the network to process sequences in both forward and backward directions, enhancing performance in tasks like named entity recognition.
- 2017: Attention mechanisms were integrated with LSTMs, leading to models like Transformer-XL, which further improved sequence modeling capabilities. Today, while newer architectures like Transformers have surpassed LSTMs in some domains, LSTMs remain widely used due to their interpretability, efficiency in certain tasks, and well-understood training dynamics.
#How It Works
#Core Components of an LSTM Unit An LSTM unit operates through a series of mathematical operations that regulate the flow of information. Each LSTM cell contains the following key elements:
- Cell State (Ct): The "memory" of the LSTM, which carries information across sequences.
- Hidden State (ht): The output of the LSTM at time step t, which is passed to the next time step.
- Gates: Three specialized neural networks that control the flow of information:
- Forget Gate (ft): Decides what information to discard from the cell state.
- Input Gate (it): Determines what new information to store in the cell state.
- Output Gate (ot): Controls what information is output to the hidden state.
#Mathematical Formulation At each time step t, the LSTM performs the following computations:
- Forget Gate: \[ f_t = \sigma(W_f \cdot [h_t-1, x_t] + b_f) \] - ( \sigma ) is the sigmoid activation function (outputs values between 0 and 1). - ( W_f ) and ( b_f ) are the weights and bias for the forget gate. - ( h_t-1 ) is the previous hidden state. - ( x_t ) is the current input.
- Input Gate: \[ i_t = \sigma(W_i \cdot [h_t-1, x_t] + b_i) \] \[ \tildeC_t = \tanh(W_C \cdot [h_t-1, x_t] + b_C) \] - ( \tildeC_t ) is the candidate cell state, computed using the tanh activation function.
- Cell State Update: \[ C_t = f_t \odot C_t-1 + i_t \odot \tildeC_t \] - ( \odot ) denotes element-wise multiplication. - The cell state is updated by combining the previous cell state (scaled by the forget gate) and the new candidate state (scaled by the input gate).
- Output Gate: \[ o_t = \sigma(W_o \cdot [h_t-1, x_t] + b_o) \] \[ h_t = o_t \odot \tanh(C_t) \] - The hidden state ( h_t ) is computed by applying the output gate to the tanh-activated cell state.
#Key Mechanisms
- Constant Error Flow: The cell state acts as a "highway" for gradients, allowing them to flow unchanged over long sequences, mitigating the vanishing gradient problem.
- Selective Retention: The gating mechanisms ensure that only relevant information is preserved, while irrelevant data is discarded.
- Non-linearity: The use of sigmoid and tanh activations introduces non-linearity, enabling the network to model complex patterns.
#Important Facts
- Vanishing Gradient Mitigation: LSTMs address the vanishing gradient problem by maintaining a constant error flow through the cell state, allowing them to learn dependencies over long sequences.
- Gating Mechanisms: The three gates (forget, input, output) enable precise control over information flow, distinguishing LSTMs from traditional RNNs.
- Parallelization Challenges: While LSTMs are powerful, they are computationally intensive and difficult to parallelize compared to feedforward networks or Transformers.
- Variants:
- Bidirectional LSTM (BiLSTM): Processes sequences in both forward and backward directions, improving performance in tasks like speech recognition.
- GRU (Gated Recurrent Unit): A simplified variant of LSTM with fewer gates, offering faster training with comparable performance in some cases.
- Attention-Based LSTMs: Integrates attention mechanisms to focus on specific parts of the input sequence, enhancing performance in tasks like machine translation.
- Applications:
- Time-Series Forecasting: Stock price prediction, weather forecasting.
- Natural Language Processing: Sentiment analysis, text generation, machine translation.
- Speech Recognition: Converting spoken language into text.
- Handwriting Recognition: Transcribing handwritten text from images.
- Training Data Requirements: LSTMs typically require large datasets to generalize well, as their complex architecture demands substantial computational resources.
- Interpretability: Unlike black-box models like Transformers, LSTMs offer more interpretable internal states, making them easier to debug and analyze.
#Timeline
- Foundational ideas
Core concepts and early methods shape What Is a LSTM (long Short-term Memory)?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does What Is a LSTM (long Short-term Memory)? cover?
Explains What Is a LSTM (long Short-term Memory), including the core definition, how it works, practical examples, and limitations.
Why is What Is a LSTM (long Short-term Memory)? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Artificial Intelligence decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as LSTM, Long, Short before using the ideas in real projects.
#References
- What Is a LSTM (long Short-term Memory)? terminology and background research
- What Is a LSTM (long Short-term Memory)? use cases, implementation examples, and limitations
- Artificial Intelligence best practices, standards, and risk guidance
- LSTM case studies, benchmarks, and current industry analysis




Comments
No comments yet. Start the discussion with a useful note.